Agentic RAG: Enterprise AI Moves Beyond Standard Retrieval

⚡ Quick Take
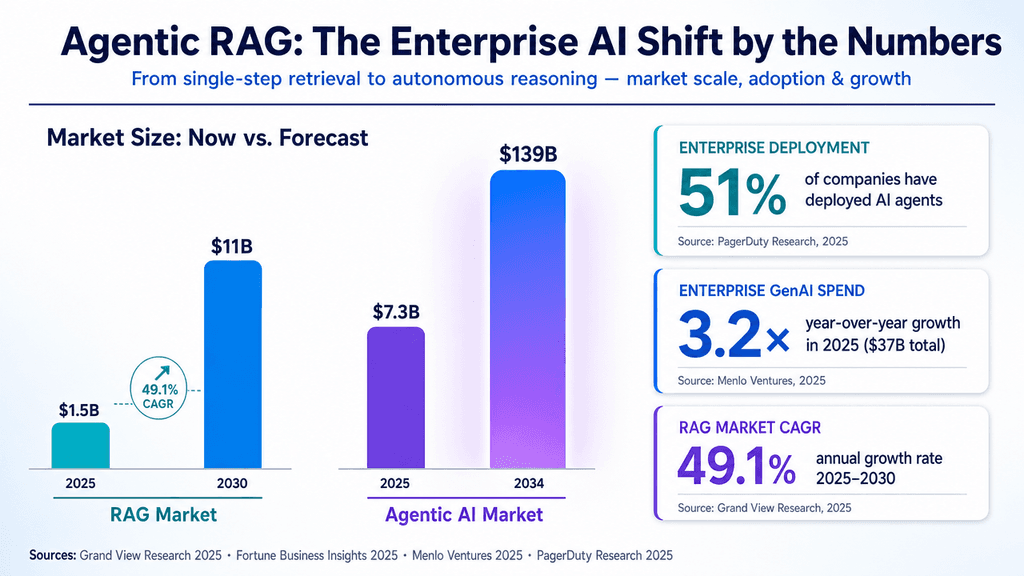
The era of "blind fetch" retrieval is ending. Enterprise AI stacks are shifting fast toward Agentic RAG - a layered setup where models don't simply pull data but plan, review, and steer their own steps to cut down on hallucinations.
Major players like Google, AWS, and NVIDIA are rebuilding their enterprise offerings around this idea. The difference from plain Retrieval-Augmented Generation is that Agentic RAG weaves in planning, live routing, and correction steps right inside the retrieval flow. That change is kicking off a fresh contest over who controls the orchestration layer.
Developers have already started moving away from single-step RAG toward agent frameworks such as LangGraph and LlamaIndex. At the same time, Google's Gemini Enterprise, AWS Bedrock, and NVIDIA are rolling out tools built for multi-hop reasoning, tighter data controls, and steady throughput.
Standard RAG has simply run into limits on scale. It stays too fragile and prone to stray answers for real enterprise work. Agentic RAG brings in ReAct patterns and feedback loops that move the focus from clever prompts to reliable systems and operations.
The shift hits enterprise CTOs first, along with LLMOps teams handling evaluations and cloud providers managing the extra compute load from repeated agent steps. One angle that gets less attention is the added latency and cost. Vendors highlight accuracy gains, yet few clear standards exist for tracking these pipelines once they grow complex.
🧠 Deep Dive
Have you ever watched a standard RAG setup collapse on anything beyond a simple lookup? In its usual form, the flow stays linear: a query comes in, vectors return a chunk of text, and the model paraphrases it. That works until the question needs several links or the data sits in different shapes. Then context drifts and answers start to wander.
Agentic RAG changes the picture by treating retrieval as a state machine. The model breaks the query apart, calls the right tools, checks what came back, and runs a repair loop when needed. At the tooling level, LangChain through LangGraph and LlamaIndex are competing to give developers nodes, memory, and clear transitions instead of flat chains. Higher up, Google positions Gemini Enterprise around governance and built-in attribution for leadership teams. AWS Bedrock leans on its security strengths, adding IAM boundaries and isolation that architects already trust.
NVIDIA watches the same move because Agentic RAG burns more compute. Each prompt can spark repeated calls, reranking, and async steps. The company is pushing GPU batching and caching layers to keep those extra hops from turning into visible delays.
Even so, the operational side still lags. Routing mistakes or slow drift in retrieval can create loops that eat through tokens with little warning. What is missing is an SRE-style approach to these systems: solid tracing with OpenTelemetry, evaluation sets focused on factual accuracy, and clear patterns for fields like finance and healthcare where lineage matters.
In short, value is sliding away from raw model weights and toward the routing logic, guardrails, and caching that sit between the user and the hardware. Concepts such as Self-RAG and Corrective RAG are becoming standard features rather than research footnotes.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
LLM & Framework Providers | High | The contest moves from model size to orchestration control. LangChain, LlamaIndex, Google, and AWS all want to become the default engine for agent behavior. |
Enterprise CTOs & Devs | High | Leaving basic RAG cuts hallucinations yet raises the bar for LLMOps work - new tracing, failure analysis, and spend tracking are now required. |
Cloud & Infra (NVIDIA, CSPs) | High | Multi-step reasoning increases token use and favors async GPU patterns plus caching to manage latency. |
Security & Regulators | Significant | Autonomous tool use brings fresh privacy and data-handling risks, so RBAC and observable controls become essential. |
✍️ About the analysis
This independent review draws from current framework docs, reference architectures, and vendor materials across Google, AWS, NVIDIA, LangChain, and LlamaIndex. It is meant for AI practitioners, platform engineers, and technology leaders who need a clear view of the architectural and market changes ahead.
🔭 i10x Perspective
Agentic RAG sits between today's chat interfaces and the autonomous agents still on the horizon. By folding reasoning into retrieval itself, the field is admitting that progress will come less from bigger base models and more from the error-catching systems built around them. In the next few years the real advantage may lie with whoever masters routing, cost control, and reliable tool use under live conditions. The large cloud providers are already moving to lock down that layer and turn complex workflows into managed offerings.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.