AI Chatbots Struggle with Real-Time Election News, Study Finds

Have you ever turned to one of the big chatbots for the latest on an election or breaking story, only to get something that feels half-baked? A fresh benchmarking study makes clear that even the strongest models—ChatGPT, Claude, Gemini, and Grok—still fall short when it comes to reliable, real-time information on elections and fast-moving news.
The researchers put the leading systems through a series of tests on live events. What surfaced were consistent gaps: weak localization, shaky citations, and plain hallucinations, even after recent search upgrades. From what I've seen in similar evaluations, these aren't one-off slips. They point to deeper limits in how the models handle anything that changes by the hour.
The first published results from some of the studies show just how wide the gap remains between model marketing and live performance.
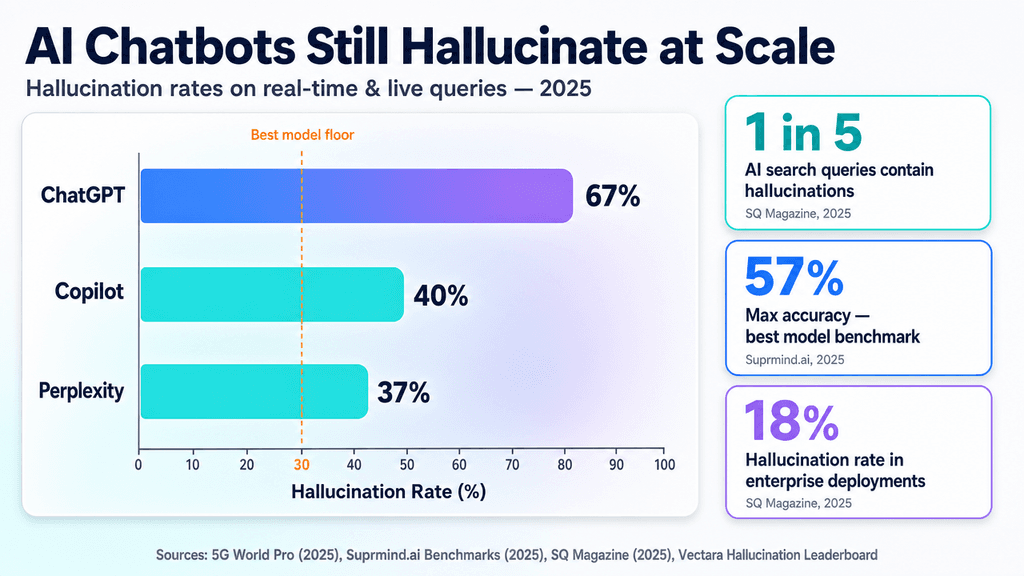
That gap matters all the more now that AI companies are pitching their tools as full search replacements. The line between what a model was trained on and what it can fetch in the moment is thinner than most marketing admits. Teams fine-tuning retrieval systems, risk officers rolling out public-facing agents, and policymakers eyeing election transparency rules feel the pressure first.
Yet the coverage so far tends to treat this as a user-education problem. The real bottleneck sits lower down: the trade-offs in speed, language coverage, and source trust that come with asking a large model to act like a high-speed fact engine.
🧠 Deep Dive
The big labs have pushed the story that conversational agents can take over from classic search. This new round of tests on ChatGPT, Claude, Gemini, and Grok pushes back on that claim. When the prompts zeroed in on shifting election details, polling logistics, and fast geopolitical developments, the outputs were uneven at best.
Looking past the usual hallucination talk, the issues trace back to a basic mismatch. Training data ages quickly, and the retrieval layers meant to patch that gap still stumble when asked to blend fresh results into coherent answers. Cross-language queries or tightly local context expose the cracks fastest.
Consumer reports rightly flag the invented dates or quotes. For people actually building these systems, though, the citation failures are more telling. There is still no agreed way to rank source reliability while the model is generating, especially when it has to sift through SEO-heavy results for something as structured as election data. Blunt guardrails remain the default fix across vendors, which often means refusing the question instead of answering it well.
What we need next is clearer tracking of how error patterns shift with each model update. Over time the contest among providers will hinge less on raw size and more on who can deliver fast, verifiable grounding that holds up under real pressure.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Forced to rethink RAG pipelines; safety teams must balance blunt refusal policies with the need for high-quality, grounded responses. |
Search Infrastructure | High | Highlights the ongoing necessity of deterministic search APIs and specialized web-scraping infrastructure to feed LLMs. |
Enterprises & Media | High | Newsrooms and commercial agents face immense brand risk if leveraging out-of-the-box LLM APIs for live-data generation without human-in-the-loop safeguards. |
Regulators & Policy | Significant | Provides quantitative ammunition for lawmakers pushing for strict election-integrity guardrails and algorithmic auditability. |
✍️ About the analysis
This independent review pulls together competitive reporting, test frameworks, and performance data across models. It is written for developers and technical leads who have to ship LLMs in settings where accuracy cannot be taken on faith.
🔭 i10x Perspective
The fact that even frontier models still trip on live news shows that raw reasoning power and dependable information retrieval are not the same skill. In the next few years, expect a split: either models move toward ongoing learning designs, or serious real-time search tasks drift back toward systems that can be audited and verified by design.
Static capability was the first milestone. Handling time-sensitive facts at scale looks like the harder stretch.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.