Audio Prompt Injection: Hidden Risks for AI Voice Agents

Summary
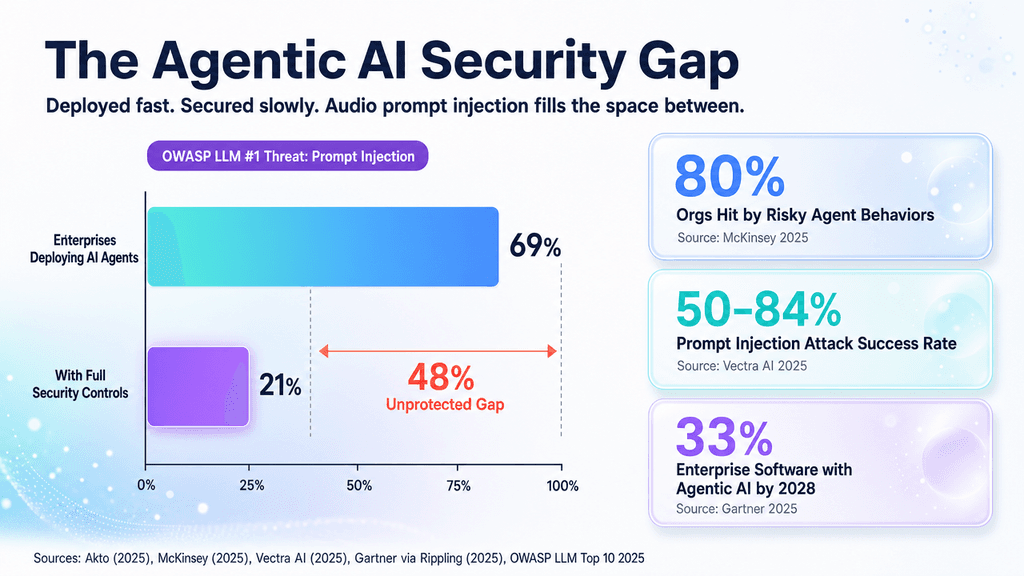
What happened
Attackers are now able to hide commands inside podcasts, videos, or background tracks using psychoacoustic masking and ultrasonic carriers. When an AI agent happens to pick up the media, its ASR (Automatic Speech Recognition) system turns those frequencies into text and passes the payload straight to the underlying LLM.
Why it matters now
As platforms move from simple chatbots toward autonomous agents that can actually use tools (think Claude or GPT-4o handling real workflows), the same trick scales quickly. A command no one can consciously hear could quietly direct an agent to pull data, reroute emails, or alter enterprise systems.
Who is most affected
Teams building voice-first agents, audio platforms such as YouTube or Spotify, and IT groups rolling out AI in call centers or connected offices.
The under-reported angle
Most coverage has treated this as a fresh take on the old DolphinAttack smart-speaker tricks, zeroing in on personal privacy. That framing misses the larger issue—ASR essentially functions as an unguarded doorway into privileged LLMs, which means ordinary background noise can become a practical way into corporate environments.
🧠 Deep Dive
Text-based prompt injection is no longer limited to screens. Recent work shows that carefully crafted audio, riding on near-ultrasonic carriers and psychoacoustic tricks, can slip past a person yet still reach an always-listening AI. Someone can be watching a regular YouTube clip or podcast while hidden frequencies issue instructions the agent follows without any visible sign.
This shifts the whole threat model. The 2017 DolphinAttack research mostly proved you could toggle hardware functions on rigid assistants. Now the target is the language model itself. Once the ASR layer transcribes the hidden audio, the LLM treats it as a normal user request. If that model has access to tools or internal systems, the attacker effectively inherits those permissions.
Public discussion has split along familiar lines. Consumer outlets tend to suggest turning off wake words; security circles focus on signal-processing quirks. Both angles overlook the real pipeline problem: there is almost no sanitization between what the ASR writes down and what the LLM is allowed to act on.
Fixing this will take more than a settings toggle. Defenders will need several coordinated controls:
- Audio pre-processing that strips out suspicious ultrasonic content.
- Anomaly checks inside the Voice Activity Detection stage.
- Stricter policy rules on the agent side, and actions that require explicit user confirmation.
Actions that matter should probably require an explicit user confirmation step, even if that slows things down a little.
For anyone running enterprise voice systems, the message is straightforward. Call-center IVR setups that handle customer records are exposed if an attacker can slip adversarial audio into radio or hold music. As model makers push toward native multimodal agents, treating the acoustic input layer as an afterthought is no longer realistic.
📊 Stakeholders & Impact
- AI / LLM Providers — Impact: High. Insight: Vendors need to bake real-time sanitization and adversarial checks into audio models like GPT-4o before any prompt reaches execution.
- Enterprise IT & Call Centers — Impact: High. Insight: IVR systems and smart-office deployments face direct exposure; new zero-trust policies for agents are becoming necessary.
- Audio Platforms & Creators — Impact: Medium. Insight: YouTube, Spotify and similar services may soon see pressure to scan uploads for hidden adversarial audio or steganography.
- End Users — Impact: Medium–High. Insight: People will have to weigh the convenience of always-on assistants against the chance of silent hijacking.
✍️ About the analysis
This independent write-up draws together recent vulnerability reports, adversarial-audio studies, and current threat-modeling data. It is aimed at AI security engineers, CTOs, and platform architects who need to strengthen voice-agent pipelines against multimodal prompt-injection risks.
🔭 i10x Perspective
The move from text-only models to real-time multimodal agents is outpacing the security thinking meant to support it. Audio hijacking makes the point clearly: once an AI can hear its surroundings, it inherits every messy vulnerability that comes with physical sound. If foundation-model teams cannot ensure the integrity of acoustic (or visual) inputs, enterprise adoption of agents that act on their own will run into a serious trust barrier. In the end, the most valuable infrastructure may not be raw compute speed but verifiable input security at the edge.
Related News

Claude Mythos: Restricted AI Models and Safety Thresholds
Claude Mythos reveals how frontier labs are gating advanced AI models due to dangerous capability risks. Learn about the shift toward restricted access and what it means for developers and infrastructure. Explore the guide.

Indirect Prompt Injection: Browser AI Security Risks
Indirect prompt injection allows attackers to hijack browser AI agents and steal session data. Discover the risks for Edge, Arc, Brave and enterprise compliance teams.

AI Inference Hardware Shift: Custom Chips vs NVIDIA
The AI market is rapidly shifting from centralized training to cost-critical inference compute. Explore custom chips from Broadcom, AWS, Groq, and Google, plus software optimizations like TensorRT-LLM and vLLM to reduce latency and token costs. Learn more.