DeepSeek V4 on B.AI: Flash & Pro Models Explained

DeepSeek V4: Flash & Pro on B.AI — Quick Take
⚡ Quick Take
DeepSeek V4 has quietly entered the infrastructure ecosystem, with platforms like B.AI upgrading services for the new 'Flash' and 'Pro' models tailored for high-stakes crypto and AI workloads.
Summary: B.AI has officially completed infrastructure upgrades to support DeepSeek-V4-Flash and DeepSeek-V4-Pro, optimizing their platform for latency-sensitive and reasoning-heavy tasks.
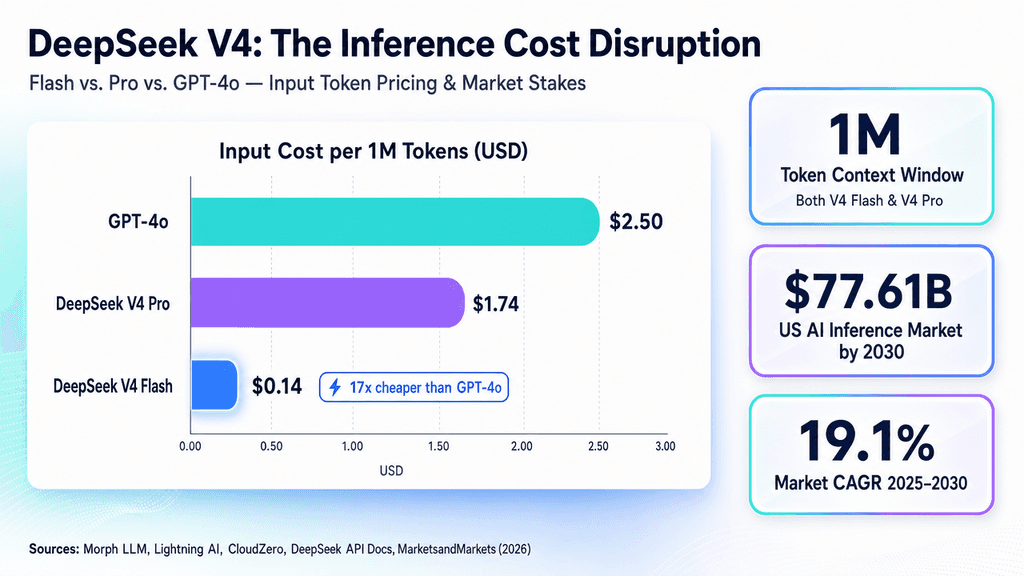
What happened: The rollout introduces two distinct tiers of DeepSeek's latest architecture - a Flash variant designed for cost and speed, and a Pro variant built for complex output and accuracy - specifically targeted at the algorithmic crypto and on-chain analytics ecosystem.
Why it matters now: As highly specialized, low-latency applications like crypto trading bots integrate LLMs, the demand for ultra-fast, structured outputs (like guaranteed JSON via function calling) is pushing AI infrastructure away from generic cloud environments toward custom, hyper-optimized inference pipelines.
Who is most affected: AI developers, algorithmic and quantitative traders, and alternative cloud infrastructure providers looking to undercut mainstream API costs for high-throughput inference.
The under-reported angle: Current coverage is heavily PR-driven and completely lacks actionable technical data. Official announcements are missing crucial p95 latency benchmarks, context window limits, token pricing, and SDK quick-starts - the metrics engineering teams actually need to deploy these models to production.
🧠 Deep Dive
Have you ever tried wiring a frontier model into a live trading system only to hit a wall of missing specs? The deployment of DeepSeek V4 - split into "Flash" for raw throughput and "Pro" for high-fidelity reasoning - marks a critical pivot in how frontier-class open-weight models are brought to market. By surfacing through specialized infrastructure providers like B.AI rather than generic hyperscalers, DeepSeek is directly courting niche, hyper-demanding developer ecosystems. In this case, the target is crypto algorithmic trading and on-chain analytics networks, a sector where millisecond latency and flawless structured JSON outputs are existential requirements for executing trades and auditing smart contracts.
That said, the current industry coverage surrounding this launch is strikingly hollow. PR announcements applaud the "service upgrades" but fail to provide the actual telemetry that AI engineering teams rely on. There is a glaring absence of concrete specifications: no verified context window sizes, missing p50/p95 latency throughput numbers, and zero mention of competitive token pricing against models like GPT-4o-mini or Claude 3.5 Haiku. For developers attempting to build latency-bound RAG pipelines or market-making bots, this lack of documentation creates an immediate adoption bottleneck.
To truly optimize these workloads, the ecosystem requires engineer-first transparency. If DeepSeek-V4-Flash is going to power real-time risk engines, developers need transparent SDK quick-starts (Python/JS), explicit concurrency limits, and strict SLA guarantees for API uptime. Without rigorous MT-Bench or MMLU evaluation disclosures to map capability degradation against speed, the claim of "better support for AI workloads" remains unverified marketing.
Beneath the surface, this rollout highlights a rapidly accelerating trend in AI infrastructure: the rise of specialized, boutique inference hubs. As foundation models become increasingly commoditized, the true differentiator shifts to infrastructural performance at the edge. Platforms like B.AI are attempting to solve the specific latency-vs-cost trade-offs that hold companies back from deploying AI in high-frequency environments.
Ultimately, the DeepSeek V4 and B.AI integration is a stress test for alternative AI ecosystems. To succeed against the reigning API giants, these alternative providers must move beyond announcement-driven hype and deliver the reproducible benchmarks, cost-per-token calculators, and MLOps compliance playbooks that regulated, production-grade engineers demand.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | DeepSeek’s two-tier approach (Flash/Pro) challenges Western AI incumbents by targeting specific price-to-performance niches. |
Inference Infrastructure | High | Providers like B.AI must prove they can deliver the scalable hardware, prompt caching, and low-latency APIs required by high-frequency workloads. |
AI / Fintech Developers | Medium-High | Offers potential for massive cost reductions in agentic pipelines, provided the models support reliable function calling and error backoffs. |
Cloud Incumbents | Low-Medium | Signals growing market fragmentation; boutique infrastructures are successfully capturing niche, workload-specific LLM demand. |
✍️ About the analysis
This independent, research-based analysis draws on competitive coverage mapping and identifies systemic capability application gaps surrounding the DeepSeek V4 deployment. It is synthesized specifically for AI developers, infrastructure engineers, and CTOs evaluating cost, latency, and hardware trade-offs in alternative LLM environments.
🔭 i10x Perspective
The quiet rise of specialized infrastructural partnerships - like DeepSeek V4 running on B.AI for programmatic crypto use cases - signals a fractured, highly targeted future for LLM delivery. From what I've seen, we are rapidly moving past the era of generic "one-size-fits-all" APIs; the next intelligence frontier will be defined by workload-specific routing where specialized telemetry, hardware mapping, and strict latency SLAs dictate market share. As alternative models aggressively close the parity gap with OpenAI and Anthropic, the true competitive moat for the next five years will shift entirely from raw cognitive capability to inference unit economics.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.