Google AI Weak Verifiers Boost Spatial Reasoning Accuracy

Summary
Google AI has introduced a framework that taps Large Language Models to generate executable "weak verifier" programs. These snippets get bundled together to steer and check complex spatial layouts, sidestepping the usual brittle hand-coded rules.
What happened
Rather than locking spatial constraints into fixed code, the team asked LLMs to write task-specific checkers straight from natural-language descriptions. Pooling many of these individually "weak" and sometimes noisy verifiers produces a surprisingly sturdy signal for validating spatial work.
Why it matters now
Spatial reasoning still trips up transformer models on a regular basis. Treating program synthesis as a verification layer marks a structural change, nudging the field toward self-contained loops where models essentially serve as their own QA layer.
Who is most affected
Researchers working on agentic systems, engineers handling robotics or chip layouts, and developers building procedural content in games.
The under-reported angle
Most coverage frames this as a generative-design aid, yet it quietly competes with classical constraint solvers such as SAT or SMT. Running thousands of auto-written checks also raises fresh sandboxing and security questions that have received little attention so far.
🧠 Deep Dive
Have you ever watched an LLM propose a floor plan or warehouse layout that collapses the moment you test basic clearance rules? Spatial reasoning remains one of the more stubborn gaps in current models. In the past, teams tried to contain the problem with lengthy, hand-written constraint engines that proved difficult to maintain or extend. Google AI is testing a different route: instead of forcing the model to produce a flawless layout on its own, they ask it to generate the code that will later judge any layout.
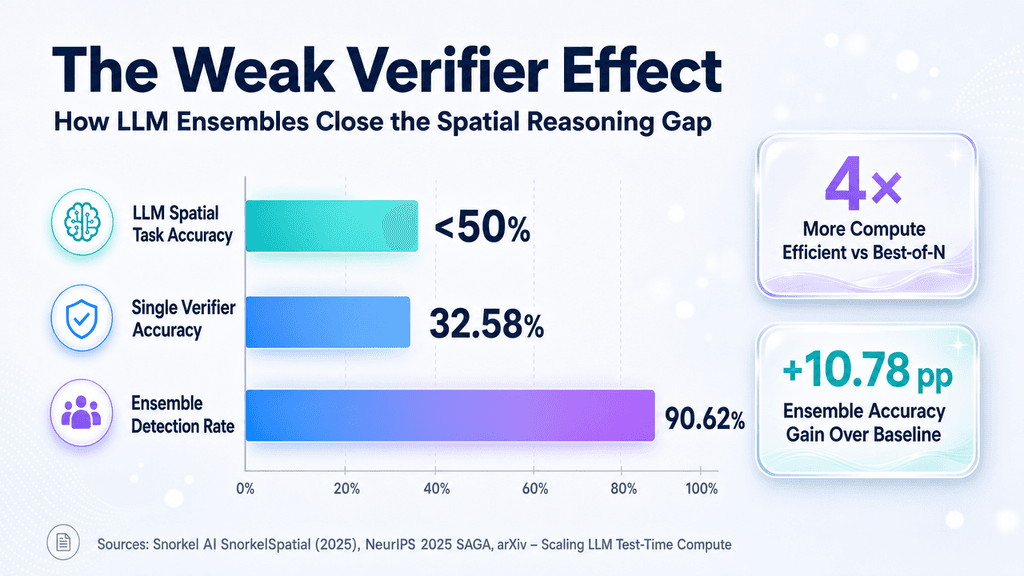
The real leverage comes from scale. A single LLM-written verifier tends to be incomplete or noisy, yet prompting the model for dozens of distinct checkers and combining their outputs creates a collective signal that is far more reliable than any one piece. This shifts validation away from rigid, manually engineered logic toward something closer to probabilistic consensus built on the fly.
Discussions on forums like GameDev.net often treat the work as another tool for level design and procedural generation. That view underplays the larger direction. The approach essentially applies test-time compute to spatial constraints, letting models extract rules for flow, symmetry, and connectivity without requiring weeks of solver tuning. Over time it could encroach on territory long held by ILP, SAT, and SMT engines, especially for tasks where constraints stay somewhat ambiguous.
Still, practical questions linger. Running repeated self-checks at volume forces trade-offs around latency and cost that many teams will feel immediately. More pressing, executing auto-generated constraint code at any real scale demands secure, isolated environments—an infrastructure requirement that has not yet been widely discussed.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Points toward greater emphasis on test-time reasoning and program synthesis rather than pure generative capability. |
PCG & Spatial Devs | High | Moves teams from hand-coded spatial rules toward prompt-driven verification, which can shorten iteration cycles noticeably. |
Infra & Cloud Security | Medium-High | Will require new sandboxing patterns to run large numbers of unvetted Python or C++ snippets safely. |
Classical Solver Devs (SAT/SMT) | Medium | May face gradual displacement where probabilistic verifier ensembles prove sufficient for fuzzier spatial problems. |
✍️ About the analysis
This independent look at Google AI’s weak-verifier aggregation compares older procedural techniques with newer program-synthesis methods. It is intended for architects and developers who are weighing how agentic spatial systems might actually ship.
🔭 i10x Perspective
Taken together, these weak-verifier ensembles illustrate a broader pattern in scaling: a move from training-time computation toward richer test-time loops. When models can reliably write the code that audits their own spatial results, the foundation is in place for largely autonomous design pipelines. The next generation of systems will not only draft a circuit or building plan but also generate, execute, and confirm the necessary checks before any human review occurs. The decisive advantage is shifting from producing an answer to producing a dependable critic for that answer.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.