Google Gemini Shifts to On-Device Edge AI and XR Glasses

⚡ Quick Take
The era of cloud-bound chatbots is fracturing as Google pivots Gemini toward ambient, edge-computed intelligence powered by deeply integrated hardware.
Summary
Google I/O 2026 unleashed a massive wave of Gemini updates, embedding optimized on-device models deeply into the Android OS and revealing AI-native smart glasses designed for continuous real-world perception.
What happened
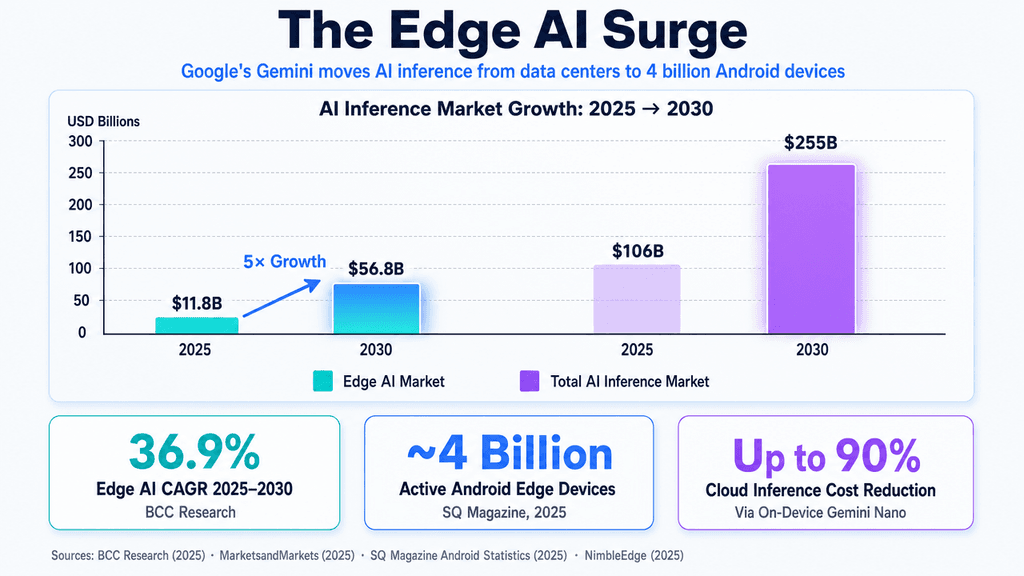
Google explicitly mapped its Gemini foundation models to local hardware, shifting the AI focus from massive cloud inferencing toward on-device Android capabilities, while previewing XR glasses that act as a persistent multimodal lens for the AI.
Why it matters now
The bottleneck in the AI race is no longer just model capability - it's latency, context limits, and inference costs. By routing multimodal reasoning directly to edge devices, Google completely alters the developer latency budget and the infrastructure required to scale AI to billions of users.
Who is most affected
Edge application builders, enterprise IT administrators managing data boundaries, hardware vendors scaling local compute requirements, and rival LLM providers lacking an integrated mobile OS.
The under-reported angle
The great infrastructure offload. Mainstream coverage treats on-device Gemini as a consumer privacy feature, but it is fundamentally a strategy to shift billions of dollars in daily server-side compute costs directly onto consumer smartphone batteries and local neural processors.
🧠 Deep Dive
If Google I/O 2026 proved one thing, it is that foundation models are evolving from discrete web services into persistent, OS-level nervous systems. While official PR blogs cheered new Workspace capabilities and mainstream tech outlets scrambled to parse which consumer features are actually shipping, the true signal lies beneath the surface. From what I've seen, Google is aggressively pushing its Gemini architecture to the edge.
By segmenting Gemini into distinct cloud and on-device tiers, Google is navigating a core physical limitation of the AI boom: the exorbitant cost of server-side inference. While competitors evaluate massive 1-Gigawatt data centers, Google is leveraging Android's billion-device footprint as an omnipresent edge-compute node. This means developers can now build latency-critical applications - such as live translation or visual parsing - without the round-trip delay to a cloud server, fundamentally changing the physics of AI application design.
The introduction of Gemini-powered Smart Glasses (XR) serves as the ultimate catalyst for this shift. As mapped by the semantic gaps in early press coverage, these glasses aren't just another wearable. They're a persistent hardware interface for "live perception." Unlike typing a prompt into a box, multimodal reasoning through XR glasses means the AI is constantly ingesting visual and auditory context. This creates profound hardware demands for local processing and real-time battery efficiency, pushing the absolute limits of current silicon architectures.
However, a glaring gap exists between Google's keynote spectacle and developer reality. Tech and startup ecosystems are increasingly impatient with "demoware." While feature matrices look impressive on stage, developers require precise API rollout timelines, latency benchmarks, and clear context-window definitions for these edge models. Similarly, enterprise architects adopting Gemini across Google Workspace are suddenly facing complex data governance questions: when a model reasons locally on an employee's phone versus analyzing data centrally in the cloud, compliance and data-loss prevention policies must be completely rewritten.
Ultimately, Google's 2026 playbook is a brutal display of vertical integration. OpenAI has the early mindshare, and Meta has the open-source weight, but neither controls the underlying mobile operating system nor the emerging XR hardware endpoints. By intertwining an ecosystem of custom silicon, Android-level intents, and physical perception hardware, Google is attempting to ensure that the next phase of the LLM revolution happens entirely on its home turf.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Forces competitors to answer how they will achieve ultra-low latency without a native mobile OS or edge-hardware ecosystem. |
Cloud & Infrastructure | Significant | Shifting compute to local devices relieves pressure on hyperscale data centers, prioritizing local NPU/GPU capabilities overhead. |
App Developers | High | Moves the development paradigm from simple cloud API calls to managing local, on-device AI system intents and battery life tradeoffs. |
Enterprise Admins | Medium–High | Requires urgent updates to corporate compliance models to track data interacting with AI at the local device level rather than in secure cloud instances. |
✍️ About the analysis
This independent, research-based analysis is aggregated from live-event competitor coverage, official product manifestos, and real-time search intent data tracking Google I/O 2026. It is designed for AI developers, infrastructure strategists, and enterprise technology leaders seeking to understand the deployment realities beyond the keynote hype.
🔭 i10x Perspective
The deployment of Gemini into Android OS and persistent XR hardware marks the end of "declarative AI," where humans explicitly talk to machines, and the beginning of "ambient intelligence," where machines continuously observe the physical world. By decentralizing inference capabilities to the edge, Google is decentralizing the bottleneck of AI scale. Over the next five to ten years, observers should watch a heavy geopolitical and regulatory tension unfold: as live, multimodal models exist omnipresently in our glasses and phones, the battle lines will shift from "who has the largest compute cluster" to "who is permitted to process our localized, real-time reality."
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.