Grounded Generation: Making Enterprise LLMs Reliable

⚡ Quick Take
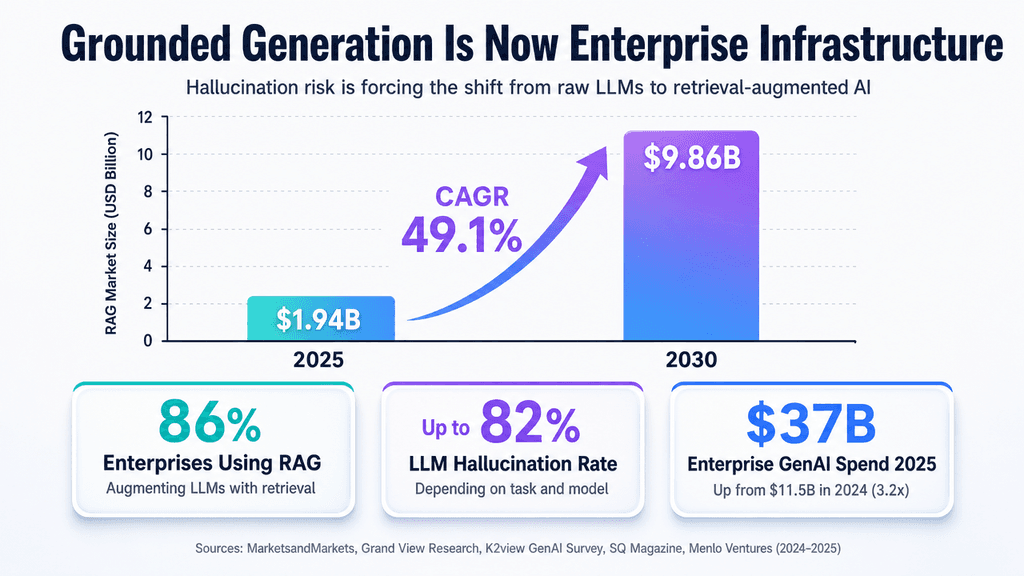
Grounded Generation — tying LLM outputs to fresh web or enterprise data so hallucinations become less of a liability — is replacing standalone models as the practical path for enterprise adoption. The last few months have turned into something of a localized race around trust. Google folded live Search straight into Vertex AI, Microsoft anchored Copilot inside each customer's Graph data, and specialists like Cohere and Vectara added native citations plus groundedness scores right in their APIs.
The reason this feels urgent now is simple: blind generation carries too much risk for real organizations. Grounding turns an LLM from a creative but unpredictable engine into something closer to a reliable utility layer that can be audited.
That shift lands hardest on AI product managers, ML engineers, and enterprise CTOs who now face the classic build-vs-buy choice — managed cloud grounding or custom RAG pipelines.
One angle that doesn't get enough attention is the real friction: not retrieval itself, but the latency hit from live search, the missing standards for measuring quality, and the extra UX work needed to surface citations so users actually trust them.
🧠 Deep Dive
Have you ever watched an otherwise capable model confidently invent details because its training data simply didn't cover the question? That limitation sits at the heart of why grounding has moved from niche experiment to required infrastructure. Instead of leaning only on a model's parametric memory, grounding injects fresh, verifiable context so the LLM functions more like a reasoning engine working over supplied evidence.
Right now the vendor landscape is splitting along two lines. Microsoft is betting on closed-loop enterprise grounding, keeping Copilot's outputs inside an organization's own tenant data with all the existing access controls. Google, by contrast, is leaning into its search advantage with Managed Search Grounding in Vertex AI, letting Gemini reach open-web results in real time. For many CTOs this creates a clear fork: commit to one of the big platforms or invest in custom, provider-agnostic RAG.
From what I've seen, developers who choose to build hit a maturing but still fragmented set of tools. Some APIs now bake citation schemas directly into the generation call, which helps with attribution. Others focus on scoring how faithful the output stays to the retrieved material. Still, the practical cost shows up quickly — extra hops to a vector store or search index, re-ranking steps, and longer context windows all add up in latency and spend.
Beyond the retrieval layer, grounding is quietly reshaping both UX and MLOps. It is no longer enough to return a correct-sounding answer; teams now expect inline citations, source traces, and confidence indicators that users can act on. That requirement ripples backward into production monitoring, because any drift in the underlying data sources immediately surfaces in the model's output.
At a deeper level we're watching a trade-off take shape: raw compute keeps getting cheaper while verified, low-latency truth keeps getting more expensive. Grounded systems give up some creative range, yet they deliver the auditability and safety that healthcare, finance, and regulated environments demand. The teams that master thoughtful caching, smart re-ranking budgets, and reliable multilingual retrieval will likely set the pace for production AI over the next few cycles.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI Model & Cloud Vendors | High | Grounding is turning into a real differentiator; platforms that already own search or rich enterprise graphs hold clear distribution edges. |
MLOps & Infrastructure Teams | High | The work now includes vector databases, hybrid indexes, and live dashboards that watch both latency and source quality. |
Enterprise CTOs & Governance | Significant | Proper grounding finally makes it realistic to use LLMs on sensitive PII or SOC 2 workloads because every claim can be traced. |
End Users / Knowledge Workers | Medium–High | The experience moves from blind acceptance toward active verification as citations become a standard part of the interface. |
✍️ About the analysis
This independent overview draws on public technical docs and product announcements from Google Vertex AI, Microsoft 365 Copilot, Cohere, and Vectara. It is meant for infrastructure leaders and MLOps teams who are steering their organizations from raw language models toward systems that can be trusted in production.
🔭 i10x Perspective
Grounding functions as a practical fix for today's LLM weaknesses, yet it also shifts where lasting value is created — moving emphasis from model weights toward the quality and freshness of the retrieval index. Over the next five years I expect we'll see hardware and software stacks purpose-built around low-latency retrieval, with the lines between search engines, vector stores, and inference hardware growing increasingly blurred. The organizations that end up ahead will be those that control efficient, high-fidelity pipelines for keeping AI tied to reality, not simply those training the largest models.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.