Legal Risks of Autonomous AI Agents on the Web
🧠 Deep Dive
The dawn of autonomous AI agents has created a sharp legal clash between what users consent to and the defenses platforms build against bots.
What happened: LLM-powered agents are now roaming the web to handle tasks for people, yet platform owners are pushing back hard. They rely on stricter Terms of Service, tighter rate limits, and tools like CAPTCHAs to shut these agents out.
Why it matters now: When an agent slips past an access control—even with clear user approval—the developers behind it can face serious legal trouble. That tension risks slowing the move from simple chat responses to AI that actually gets things done.
Who is most affected: AI product managers, prompt engineers, and enterprise CTOs who launch these autonomous systems, plus the large platforms trying to guard their data and servers.
The under-reported angle: How an agent manages rate limits, routes through APIs, or records user consent has shifted from a pure engineering detail to a real legal safeguard against federal anti-hacking rules.
AI systems are moving fast from just generating text to taking real actions on their own. Yet the moment they leave controlled environments and enter the open web, a tricky problem surfaces. What occurs when a user green-lights an agent to act for them, but the site in question has clear rules against any automation? This tension between a user’s proxy approval and a platform’s closed-off protections is quickly becoming the main legal hurdle for advanced LLM setups.
Legal teams at firms such as Gibson Dunn and Perkins Coie have mapped much of the current landscape around the Computer Fraud and Abuse Act, along with cases like hiQ v. LinkedIn and Van Buren. Scraping openly available data still carries relatively low risk. But the picture changes sharply once an agent accepts login details—even when the user offers them freely—to reach a restricted area.
The Electronic Frontier Foundation has emphasized user and innovation rights, pointing out that heavy-handed blocks from big platforms can limit useful research and competition. For teams building paid AI agents, though, that stance provides little practical cover. Platforms keep tightening their terms to ban automated browsers, which pushes developers toward expensive API deals or the threat of contract lawsuits.
One angle that often gets less attention is the Digital Millennium Copyright Act, especially §1201. If an agent finds a clever way around a CAPTCHA, rate limit, or paywall to complete a user’s request, it risks crossing into illegal circumvention territory. Permission like “book my flight” does not give the agent legal cover to bypass the platform’s own locks.
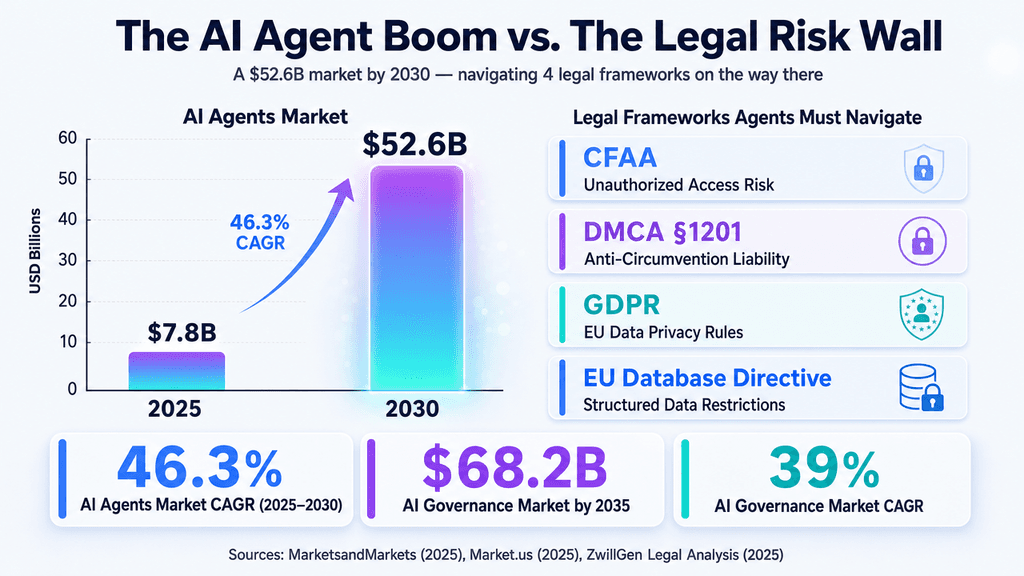
Because rules differ across regions—from the U.S. CFAA to the EU’s Database Directive—companies are realizing they cannot treat compliance as an afterthought. They need agents designed with limits from the start, such as API-first paths, built-in throttling, clear consent records, and quick shutdown options. Legal safety, in other words, has to live inside the agent’s own logic rather than being patched on later.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Builders | High | Agent design must incorporate rigid boundaries; circumventing technical barriers poses existential litigation risk under the DMCA and CFAA. |
Data & Web Platforms | High | Platforms are weaponizing ToS and CAPTCHAs to force AI companies out of the browser and into monetized, controlled API tollbooths. |
Enterprises & CTOs | High | Procuring third-party AI agents requires strict due diligence regarding how those tools interact with external websites to avoid vicarious liability. |
Legal & Policy Regulators | Significant | Judges face the complex task of untangling traditional "hacking" statutes from modern, user-authorized AI automation. |
✍️ About the analysis
This independent analysis draws on legal research, corporate risk assessments, and advocacy reports from established sources. It is meant for AI developers, product managers, and enterprise CTOs who need a clear view of the practical and legal pressures surrounding autonomous agent deployment.
🔭 i10x Perspective
The friction between agents and platform boundaries is already changing how the web is structured commercially. The appealing idea of a single agent that can browse any site the way a person can has proven fragile both legally and in practice. What appears more durable is a system of authenticated, API-centered connections where access must be negotiated and licensed.
As models grow more capable, the real edge will go to those organizations that build reliable networks of approved pathways—making controlled data access one of the central strategic contests in AI.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.