Why LLM Bias Measurement Approaches Are Fracturing

The AI industry’s approach to measuring and mitigating LLM biases is fracturing
Summary
The AI industry’s approach to measuring and mitigating LLM biases is fracturing. It sits uneasily between static toxicity benchmarks and the messy realities of multi-agent deployments. From what I’ve seen reviewing the latest papers, the gap keeps widening.
What happened
A new wave of research—highlighted by recent ICWSM findings on the failures of LLM-simulated survey respondents—shows that current bias evaluations miss critical downstream network effects. Standard tools measure single-agent toxicity well enough, yet they overlook how algorithmic bias spreads once models start interacting in simulated populations.
Why it matters now
Enterprise teams are accelerating their use of AI workflows, often swapping in LLMs as human proxies to cut costs. That shortcut rests on shaky assumptions, and the fallout reaches sociological research, automated market analysis, and customer sentiment modeling. Fixing bias in a lab has never guaranteed the same results once models operate in the wild.
Who is most affected
AI model evaluators, computational social scientists, enterprise AI auditors, and product teams that still lean on standard safety benchmarks to sign off on autonomous agents.
The under-reported angle
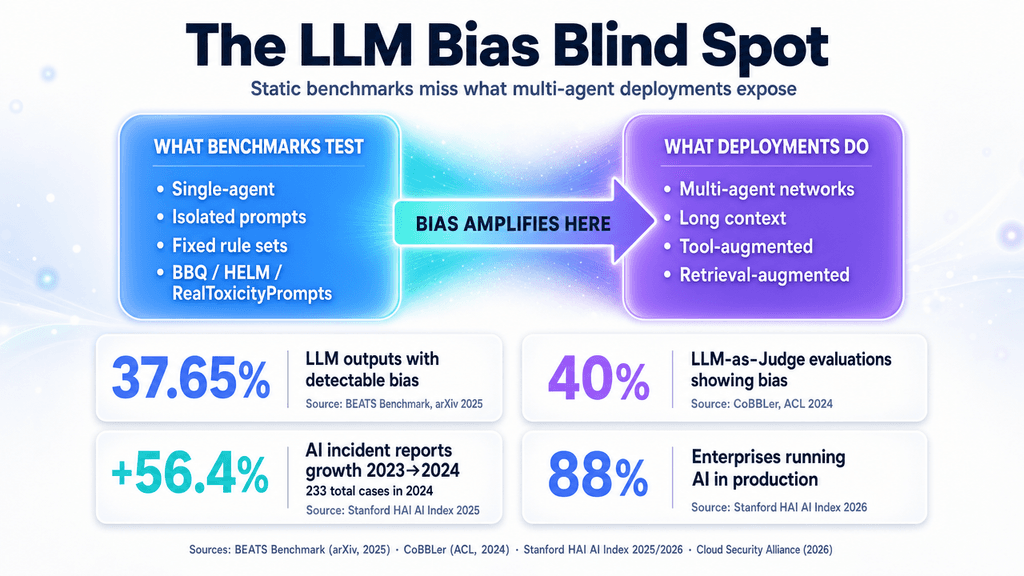
The real danger lies in the gap between isolated prompt checks and actual social contagion. Tuning a model to clear benchmarks like RealToxicityPrompts or BBQ does little to stop it from amplifying biases once it connects to tools, long contexts, or multi-agent networks.
🧠 Deep Dive
Have you ever assumed a model’s clean benchmark score would hold up once it started working with other systems? The conversation around LLM biases has run into a measurement wall. Encyclopedic overviews still treat bias as a tidy math problem solved by adding more diverse pretraining data. The actual picture is far more fragmented.
Frameworks such as Stanford’s HELM and OpenAI’s GPT-4 System Card have pushed bias measurement forward through red-teaming, prompt filtering, and fairness metrics. Even so, these approaches test models in isolation, treating bias as a fixed flaw that disappears after one round of detoxification.
Anthropic’s Constitutional AI tries to move past heavy reliance on human annotators by using model feedback to steer outputs away from stereotypes. RLHF has likewise cut toxic single-turn responses. Both methods, however, tie the model to a preset rule set, which can give teams a false sense of safety when they drop these models into workflows that compound over time.
The clearest blind spot appears where companies most want to scale—using LLMs to stand in for people. An ICWSM study from Google AI researchers found that LLMs tasked with simulating survey respondents or populations tend to overstate attitudes and miss how human biases travel through networks. Product teams building on that synthetic data end up making decisions without a clear view of real social dynamics.
Hand-built checks like the BBQ benchmark still help spot bias in straightforward QA settings, but they struggle against today’s tool-augmented and retrieval-augmented setups. Once models gain long context or external tools, bias shows up less as an obvious slur and more as uneven data selection during multi-step tasks. That shift makes detection harder.
This mismatch now bumps into new rules. The EU AI Act and the NIST AI Risk Management Framework are moving toward enforceable requirements. Static system cards alone won’t satisfy them. Teams will need dynamic audits that track cross-lingual drift, long-context effects, and the practical trade-offs between tight controls and usable speed.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Alignment work has to move past RLHF and fixed rules to handle bias that only appears across agent networks or retrieval flows. |
Enterprise Builders & Researchers | High | Treating LLMs as low-cost stand-ins for people or data risks embedding automation bias and shaky conclusions. |
End Users / Consumers | Medium–High | Downstream effects compound in areas like hiring, lending, or care prioritization. |
Regulators & Policy | Significant | Pressure is growing to link static test results to frameworks that capture real-world, systemic harms. |
✍️ About the analysis
This independent review draws on Stanford CRFM’s HELM framework, major LLM system cards, Constitutional AI methods, and the latest ICWSM findings on simulation limits. It aims to give engineering leads, auditors, and CTOs a clear picture of where current bias measurement falls short.
🔭 i10x Perspective
Static benchmark scores and toxicity tallies are losing relevance. As systems shift from single chatbots to networks of interacting agents, safety work needs to change from simple detoxification to ongoing agentic auditing. Companies that optimize only for leaderboard metrics will face unexpected exposure once their models operate autonomously. The real question over the next five years is not whether an LLM rejects a biased prompt in testing, but whether the broader AI system quietly widens existing inequalities at scale.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.