LLM Observability with Langfuse: Production Engineering
⚡ Quick Take
Summary: The operationalization of LLMs is shifting from ad-hoc scripting to rigorous engineering, with the open-source Langfuse pipeline emerging as a standard blueprint for LLM observability and evaluation.
What happened: Developer ecosystems are rapidly adopting end-to-end observability pipelines—like those built on Langfuse—to trace LLM calls, manage prompt versions, and execute "LLM-as-a-judge" evaluations within enterprise workflows.
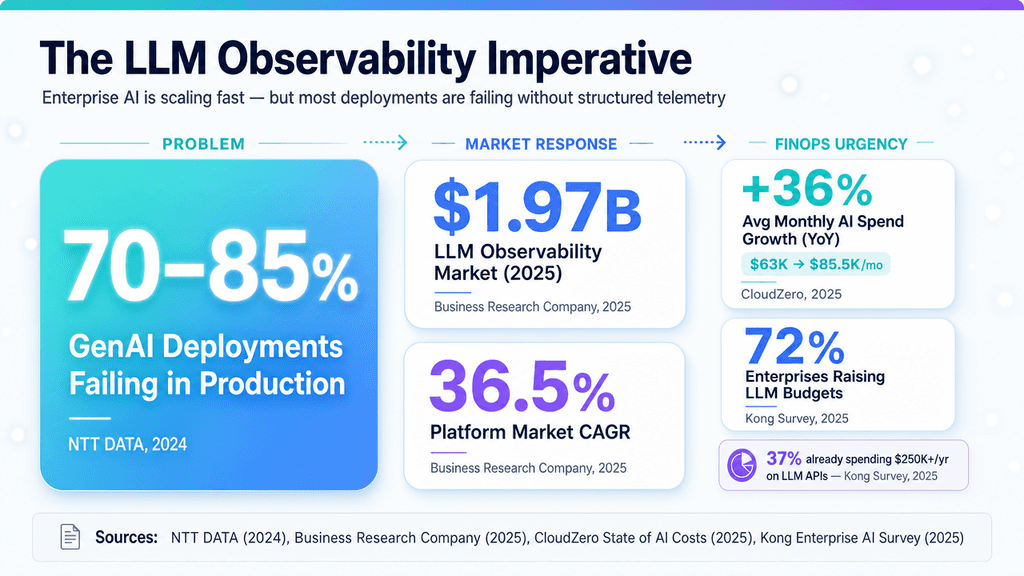
Why it matters now: As enterprise AI deployments scale, "vibes-based" evaluations are failing. Teams need structured telemetry to track latency, token costs, and prompt drift before a model change breaks a production environment.
Who is most affected: AI application engineers, MLOps platform teams, and technical leadership who must bridge the gap between experimental LLM prototypes and deterministic, compliant software engineering.
The under-reported angle: While tutorials heavily focus on basic SDK integration and tracing, the actual enterprise bottleneck is combining AI observability with enterprise FinOps, automated CI/CD gating, and strict PII redaction rules.
🧠 Deep Dive
Have you ever shipped what felt like a solid LLM feature, only to watch it degrade quietly in production? The LLM honeymoon phase is over. Building a basic wrapper around an API is trivial, yet maintaining a production-grade generative application remains notoriously chaotic. That's where rigorous LLM observability pipelines come in. Platforms like Langfuse are gaining real traction by treating probabilistic outputs with the same discipline we apply to deterministic code. They offer a centralized system for tracing, prompt management, and algorithmic scoring—attempting, at least, to tame the unpredictability that still defines these models.
At the core of this shift lies the need to eliminate prompt drift and opaque failures. Most current documentation emphasizes span schemas and multi-language SDKs because they solve immediate pain points. When an LLM chain hallucinates or fails, granular tracing lets developers look under the hood and pinpoint exactly which module—retrieval, prompt construction, or generation—caused the issue.
Yet simply logging API calls no longer suffices for large-scale deployments. The critical blind spot, and where forward-thinking teams are pivoting, is automated CI/CD integration. Instead of manual human-in-the-loop testing, sophisticated pipelines now treat datasets and scoring schemas as immutable build artifacts. If a new prompt variant degrades RAG faithfulness or pushes token consumption past a threshold, the pipeline blocks the merge outright.
From what I've seen, the open-source community loves quick starts and single-command setups. The quieter enterprise struggle centers on FinOps and compliance, though. Real production pipelines must route telemetry data through OpenTelemetry exports, stream usage metrics into data warehouses for cost analysis, and apply privacy-by-default measures like PII redaction. Managing latency and spend at scale then requires careful sampling, retention policies, and budget alerts tied to trace metadata.
Ultimately, frameworks like Langfuse reflect the maturing AI developer stack. We're moving away from isolated notebooks toward cohesive datasets, structured A/B testing, and multi-environment deployments. The competitive edge in AI is shifting too—it's less about the smartest foundational model and more about the infrastructure that makes using it safe, auditable, and economically viable.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
LLM App Developers | High | Shifts daily workflows from subjective manual testing to data-driven A/B testing and automated, dataset-backed evaluations. |
Platform & MLOps Teams | High | Tasked with deploying scalable AI infrastructure, managing OpenTelemetry integrations, and enforcing strict CI/CD quality gates. |
FinOps & Compliance | Significant | Requires granular visibility into token costs and latency, demanding strict PII redaction and RBAC (Role-Based Access Control) for AI telemetry. |
Model Providers (OpenAI, Anthropic) | Medium | Increased observability makes developers hyper-aware of model latency, cost variance, and quality degradation across version updates. |
✍️ About the analysis
This is an independent, research-based analysis of the evolving LLM observability and evaluation landscape, utilizing content gap metrics, search intent data, and developer discourse surrounding the Langfuse ecosystem. It is designed for CTOs, AI platform engineers, and MLOps leaders navigating the complex transition from AI prototyping to production-grade deployment.
🔭 i10x Perspective
The rise of multi-layered observability pipelines signals the end of casual "prompt engineering" as a standalone discipline. As open-source challengers compete with incumbents like LangSmith for developer attention, the winner will be whichever platform best connects granular AI telemetry with legacy enterprise data warehouses and governance frameworks. Over the next five years, rigorous AI observability will likely become an invisible but strictly enforced standard—without it, deploying a generative model could feel as negligent as shipping uncompiled code.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.