LLM Referral Traffic: Higher Conversions, Lower Retention

Summary
As AI search engines and LLM (Large Language Models)-powered assistants siphon market share from traditional search, a new data reality is emerging: LLM referral traffic might convert higher, but it isn't inherently stickier.
Early market data suggests that traffic referred by Large Language Models is highly transactional but struggles to retain users long-term compared to traditional search. As marketing and tech leaders rush to optimize for AI agents, they are facing massive measurement blindspots and a fundamental misunderstanding of how LLM users behave.
What happened
Cohort analyses and industry warnings are beginning to challenge the assumption that LLM-sourced traffic is a silver bullet for growth. While users occasionally click through citations provided by ChatGPT, Perplexity, or Google AI Overviews—often driving a spike in immediate conversion rates—these users rarely return sequentially to the publisher's site.
Why it matters now
As budgets pivot toward "AI Search Optimization" and brands actively court AI crawlers for Retrieval-Augmented Generation (RAG) visibility, misjudging the Lifetime Value (LTV) of an LLM-driven user could lead to massive capital misallocation. The ecosystem is blindly trading long-term brand equity for short-term, zero-click proxy answers.
Who is most affected
Digital publishers, growth marketers, enterprise data teams, and AI tool builders. SEO ecosystems are being forced to adapt, while analytics teams are struggling to build infrastructure that can properly parse AI referrers from standard web traffic.
The under-reported angle
There is virtually no standardized taxonomy for "AI Traffic." A human clicking a citation in Perplexity behaves completely differently than someone exploring a Google AI Overview or a developer querying Claude—yet most current analytics setups lump these together as "Direct" traffic, destroying attribution models and hiding the true cost of AI discovery.
Deep Dive
The topography of the web is undergoing its most radical shift since the invention of the hyperlink. LLMs like ChatGPT, Claude, and specialized search models like Perplexity are rapidly evolving from mere text generators into the primary discovery engines of the internet. But as organizations scramble to adapt to this new paradigm, early assumptions about user behavior are proving dangerously flawed.
From what I've seen, the prevailing narrative—that high-intent AI users yield highly engaged, sticky traffic—is colliding with cold cohort data. While LLM-sourced traffic often boasts higher initial micro-conversions, its long-term retention is frequently materially lower than traditional organic search.
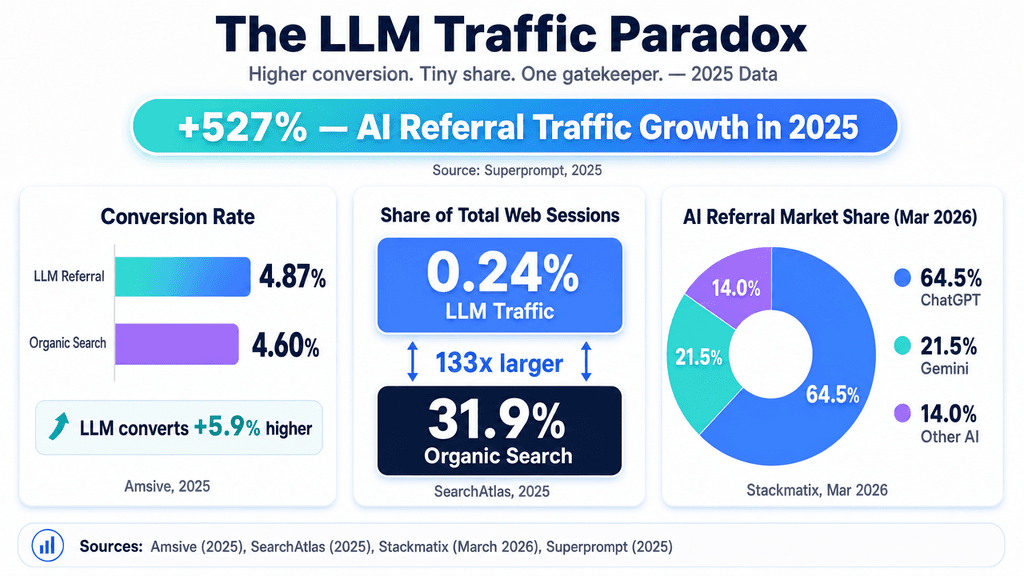
This discrepancy comes down to the fundamental nature of AI-agent interactions. A user querying an LLM is typically seeking a zero-click, definitive answer. The model acts as a permanent concierge. When a user finally does click a citation link to verify a claim or purchase a product, it is a highly transactional move, which explains the conversion spike. However, the user's loyalty remains with the AI assistant, not the destination website. The LLM acts as an aggregator, stripping away the publisher's brand stickiness and reducing the website to a mere compute node handling a temporary transaction.
Currently, infrastructure and enterprise leaders are largely flying blind through this transition. Analytics platforms built for the Google era are failing to capture the nuance of the AI web. There is a desperate need for a rigorous measurement framework and taxonomy that distinguishes between distinct AI channels: conversational assistants (ChatGPT, Claude), AI search engines (Perplexity), and AI overviews inside traditional search (Google AIO). Without strict UTM tagging, server-side data models, and complex referrer parsing, this traffic is notoriously misclassified, rendering incrementality testing and ROI modeling useless.
Beyond marketing, this behavioral shift has immediate implications for AI infrastructure and governance. To earn lucrative LLM citations, brands must allow resource-heavy AI crawlers (like OpenAI's GPTBot) to access their localized data. This creates a high-stakes tension: companies must meticulously manage their robots.txt, IP deny lists, and AI-specific meta directives to balance bandwidth costs and brand safety against the absolute necessity of being included in an LLM's grounding dataset. Organizations are being forced to decide in real-time what data to feed the models and what to lock behind paywalls to preserve actual recurring traffic.
The era of conventional SEO is fracturing into a much more complex matrix of entity relationships, schema freshness, and LLM citation density. To survive the shift, organizations must move beyond vanity metrics and deploy cohort-based stickiness models—tracking 7-day and 28-day return rates specifically by LLM platform. Only by mathematically proving the LTV of AI referrals can brands know whether they are successfully adapting to the AI ecosystem, or simply being cannibalized by it.
Stakeholders & Impact
- LLM & AI Providers — Impact: High — Insight: Models (OpenAI, Perplexity, Google) are becoming the new gatekeepers of intent, effectively replacing the browser as the primary user interface.
- Publishers & Brands — Impact: High — Insight: Forced to rebuild analytics stacks to measure high-conversion, low-retention traffic patterns, risking audience cannibalization.
- Data & Analytics Vendors — Impact: Significant — Insight: A massive window exists to build the "GA4 for the AI era," establishing new deterministic tracking for model referrers and agentic API calls.
- SEO & Growth Teams — Impact: High — Insight: Must abandon legacy keyword plays and pivot to Generative Engine Optimization (GEO), structuring data specifically for RAG ingestion.
About the analysis
This independent analysis synthesizes emerging market warnings, attribution data gaps, and semantic web research regarding LLM traffic behaviors. It is designed for CTOs, CMOs, and AI strategy leaders navigating the shifting infrastructure of digital discovery and model-driven search.
i10x Perspective
Over the next five years, the concept of "web traffic" will fundamentally bifurcate into two streams: human-driven clicks and agent-driven API interactions. As LLMs become fully autonomous agents, the value of traditional website retention will collapse, while the value of being an authoritative, real-time data node for AI models will skyrocket. The tension between publishers seeking recognizable ROI and AI vendors extracting free grounding data is unsustainable in its current form. Keep a close watch on the emergence of new business models where visual traffic is replaced by automated data-licensing micro-transactions between the AI model and the source.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.