Claude 3.5 Sonnet Availability Risks: Geopolitical LLM Impact

⚡ Quick Take
The AI ecosystem is facing a critical stress test as Anthropic’s highly capable model lineup—headlined by Claude 3.5 Sonnet—collides with sudden, sweeping geopolitical and regulatory interventions.
While Anthropic continues to push the frontier with advanced reasoning, coding, and vision capabilities across its Opus, Sonnet, and Haiku tiers, compliance mandates and recent U.S. government orders have forced localized model suspensions. Top-tier AI access is no longer guaranteed, plain and simple.
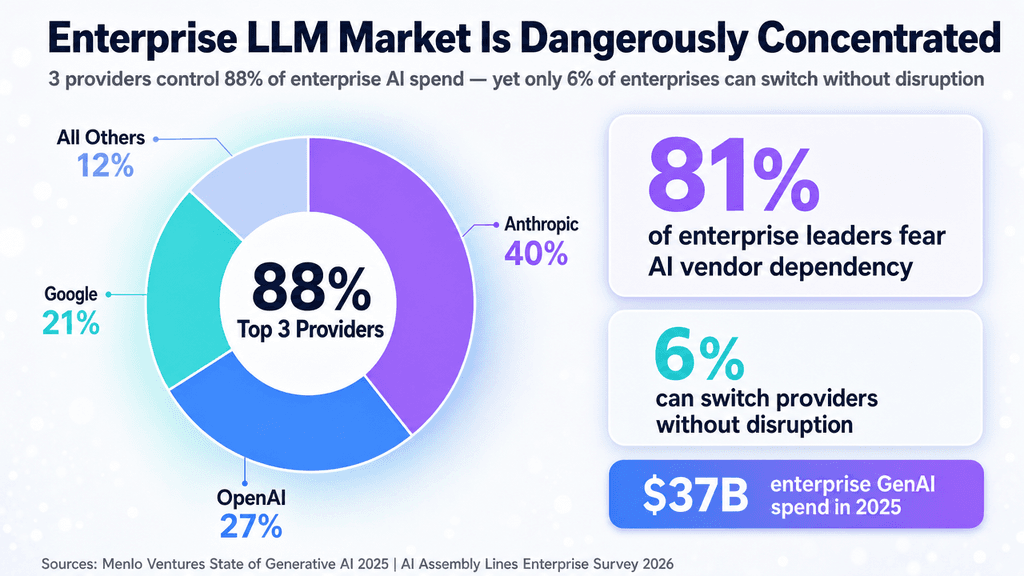
The calculus for selecting an LLM has fundamentally changed. Engineering teams can no longer base their decisions solely on API pricing, latency, and context windows; they must now architect around sovereign availability and sudden geopolitical outages.
Enterprise integration teams, technical founders, and CTOs who are deeply embedded in the Anthropic ecosystem and lack automated fallback routing to other models like GPT-4, Llama, or Gemini are most affected.
Vendor lock-in is no longer just a pricing risk—it is a catastrophic business continuity threat. Multi-model abstraction layers and "migration playbooks" have become the most critical missing pieces in today’s AI infrastructure stack.
🧠 Deep Dive
Have you ever mapped out a flawless AI rollout only to watch external forces redraw the map overnight? The way the market talks about Anthropic's Claude models is fractured into two entirely different realities. On one side, technical documentation and industry cheerleaders frame model selection as a purely rational engineering exercise: balancing the raw intelligence of Opus, the speed-to-cost ratio of Haiku, and the benchmark-breaking coding capabilities of Claude 3.5 Sonnet. On the other side, a rapidly intensifying policy landscape is reminding everyone that state-of-the-art LLMs are effectively dual-use geopolitical assets.
Recent coverage anomalies—such as reports of U.S. orders forcing sweeping shutdowns of the latest AI models—highlight a massive blind spot in current enterprise AI strategy. Procurement and IT leaders have spent the last year asking, "Which model is best for RAG or summarizing a 200,000-token document?" while completely ignoring the existential question: "What happens to our application if our API endpoint is legally mandated to go dark tomorrow?"
From what I've seen, this tension exposes substantial gaps in how AI infrastructure is being built. While Anthropic’s official guidelines provide excellent decision trees for matching tasks to performance tiers, developers are currently left without robust migration toolkits or real-world DR (disaster recovery) playbooks. The next wave of mission-critical AI applications—especially in regulated sectors like finance and healthcare—cannot survive on single-vendor dependencies. They require continuous integration and dynamic fallback mechanisms that can instantly swap a suspended generative model for an open-weight alternative without breaking the user experience.
Under the hood, this shift is transforming the intelligence supply chain. The need for real-time model status trackers, regional availability webhooks, and latency benchmarks under stress sets a new bar for AI operations. It is no longer enough for an AI provider to offer the smartest reasoning engine; they must offer ironclad SLAs, clear data governance constraints, and predictable deprecation cycles.
Anthropic’s current position perfectly encapsulates the broader AI industry’s growing pains. Pushing the frontier of coding and agentic workflows with Claude 3.5 Sonnet is a technological triumph, but scaling that compute globally means navigating a minefield of compliance. The true market winners will not just be the teams who train the best models, but the infrastructure providers who can guarantee their availability when governments start pulling the plugs.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Must shift messaging from pure benchmark supremacy to enterprise reliability, SLA guarantees, and geopolitical resilience. |
Enterprise AI Architects | High | Multi-model routing, prompt caching, and fallback abstraction layers are now mandatory for production readiness. |
Cloud Infra & Edge | Medium-High | Hyperscalers will see increased demand for multi-region hosting and sovereign cloud solutions to bypass local regulatory suspensions. |
Regulators & Policy | Significant | Governments are moving from observing AI models to actively intervening, enforcing swift compliance rules that disrupt global API access. |
✍️ About the analysis
This independent analysis synthesizes cross-platform competitor data, search intent telemetry, and regulatory tracking specifically curated for engineering managers, AI solution architects, and CTOs. It aims to bridge the gap between technical model evaluation and macroeconomic infrastructure realities, bypassing standard PR narratives to uncover actionable insights for AI procurement.
🔭 i10x Perspective
The era of blind loyalty to a single frontier model is over. Anthropic's battle to balance cutting-edge capability with stringent regulatory compliance signals a broader maturation of the AI market: intelligence is transitioning from a SaaS product to critical utility infrastructure. Over the next five years, the competitive chasm won't just be measured in benchmark wins against OpenAI or Google, but in the deployment of seamless abstraction layers that grant enterprises immunity to geopolitical whiplash. The ultimate moat is no longer just the model itself—it is the resilience of the ecosystem built around it.
Related News

AI Hallucinations: The Hidden Infrastructure Cost for Enterprises
Base models hallucinate 1 in 5 domain entities. Learn how RAG, verifier models, and factuality layers are driving AI infrastructure changes and raising compute costs. Explore the guide.

AI Agents Drive Blockchain Micropayments Race
AI agents are evolving into autonomous economic actors, spurring blockchain networks to build instant M2M payment rails. Learn how Solana, Ripple, and Lightning enable sub-cent transactions with strong custody controls. Explore the guide.

Kimi K2.7-Code: Internal Benchmarks and Transparency Gaps
Moonshot AI launched Kimi K2.7-Code with a 21.8% internal improvement claim, but lacks comparisons on public benchmarks. Explore the implications for enterprise coding AI adoption.