Google Gemini Omni: Real-Time Any-to-Any Multimodal AI

Summary
Google has officially introduced Gemini Omni, a real-time, “any-to-any” multimodal foundational model designed to natively bridge text, image, audio, and video capabilities.
What happened
Unveiled as the next evolution in the Gemini family, Omni processes and generates outputs across all modalities natively without relying on intermediate translation layers. Google has simultaneously pushed the model to Vertex AI to capture the enterprise developer ecosystem.
Why it matters now
This marks an acceleration in the multimodal arms race against OpenAI’s GPT-4o. It shifts the AI paradigm away from chained, single-function models (e.g., separate speech-to-text, LLM, and vision models) toward a unified orchestration engine capable of live, agentic tool use.
Who is most affected
Enterprise architects, CTOs, and AI platform leads, who must now re-evaluate their fragmented AI pipelines and decide whether to consolidate into a single foundational ecosystem.
The under-reported angle
While mainstream coverage is fixated on consumer-facing video demos and live conversational agents, the real battleground is Total Cost of Ownership (TCO) and governance. Google’s real advantage lies in wrapping these advanced multimodal capabilities in Vertex AI’s strict enterprise compliance wrappers.
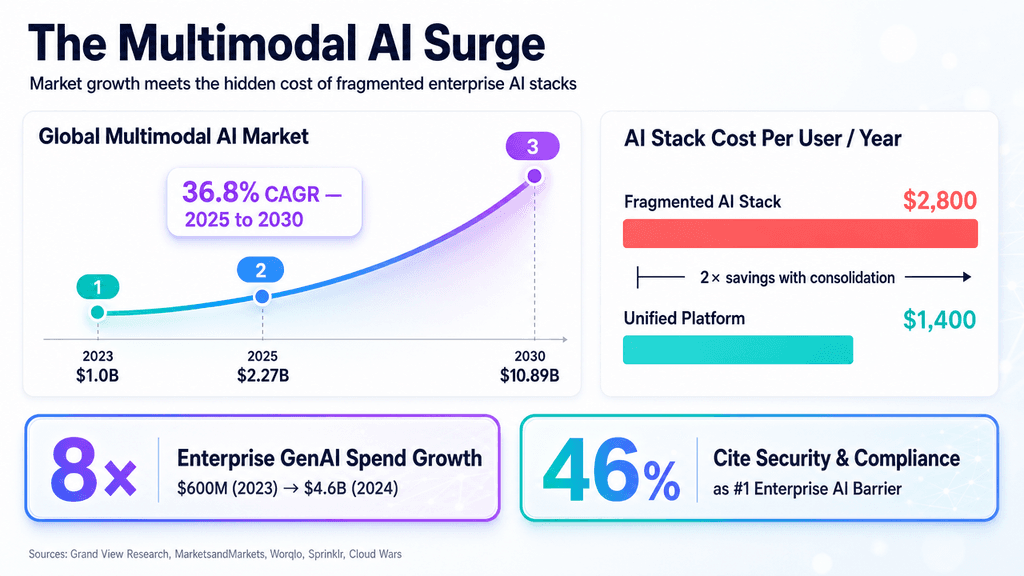
🧠 Deep Dive
Have you ever wondered why most AI tools still feel like they're stitching together separate parts? The AI industry is rapidly transitioning out of the "text-in, text-out" era, and Google’s release of Gemini Omni is the latest catalyst. Billed as an any-to-any architecture, Omni is built from the ground up to handle real-time streaming I/O across text, audio, images, and video. By eliminating the traditional API hops required to translate spoken language into text, process it, and synthesize it back into voice, Google points to a future of natively fluid, human-like agentic workflows.
From what I've seen in recent enterprise pilots, though, the glossy demonstrations aimed at consumer tech audiences mask a fiercer infrastructure war. Mainstream tech publications have largely focused on the model's consumer usability and raw latency, drawing direct comparisons to OpenAI's GPT-4o. Yet industry and vendor lenses reveal a much sharper focus on enterprise integration. Google is utilizing Vertex AI as its primary delivery vehicle, betting that the path to widespread enterprise adoption runs through data residency, observability, and function calling. For CIOs, the allure is not just a smarter chatbot; it is the promise of stack consolidation. Replacing a patchwork of specialized inference models with a single any-to-any platform fundamentally reduces integration overhead and promises to drive down the total cost per task via optimized routing.
That said, a massive gap remains in the market's current understanding: independent, repeatable benchmarks. The transformation promises of sub-second latency and seamless multimodality look spectacular in controlled demos, but migrating these to production environments with rigid SLAs is another story. Enterprises looking to implement Gemini Omni into critical workflows - such as autonomous contact centers or compliant healthcare analytics - are currently missing transparent TCO models and edge-versus-cloud performance trade-offs.
Furthermore, true enterprise deployment requires more than just low latency. It demands rigorous compliance mapping. While Google champions its built-in safety guardrails and policy evaluations, adopting an any-to-any model creates complex new vectors for hallucinations and data leakage. When a model simultaneously reasons across a live video feed and a proprietary SQL database, standard text-based red-teaming falls short. The next major hurdle for developers is building observability frameworks mapped explicitly to frameworks like HIPAA, SOC 2, and ISO 27001, ensuring that real-time multimodal data flows are as secure as they are smart.
Ultimately, Gemini Omni is a stress test for enterprise AI infrastructure. As companies begin drafting 30-60-90 day Proof of Concept (POC) playbooks for agentic systems, the challenge will shift from evaluating intelligence to evaluating industrialization. The models themselves are increasingly capable; the bottleneck is now the data governance, the network bandwidth for real-time video streaming, and the tooling required to harness an “any-to-any” reality safely.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Forces the baseline off text-only LLMs toward native, real-time multi-modality, pressuring competitors like Anthropic and Meta. |
Enterprise Architects & CTOs | High | Offers a powerful path to consolidate fragmented ML pipelines, lowering latency and API overhead, but risks deep vendor lock-in. |
Cloud Infrastructure & Edge | Medium-High | Any-to-any streaming demands massive, low-latency bandwidth, pushing the limits of current cloud-to-edge inference architectures. |
Risk & Compliance Officers | Significant | Introduces highly complex auditing challenges as proprietary data now flows dynamically across interleaved text, voice, and video. |
✍️ About the analysis
This independent, research-based analysis synthesizes current search intent, competitor technical positioning, and emerging developer content gaps. It is designed for CTOs, AI platform leads, and enterprise architects who need to look past launch demos to understand the infrastructural and governance implications of multi-modal AI deployment.
🔭 i10x Perspective
The arrival of native "any-to-any" models like Gemini Omni signals the beginning of stack collapse in the AI ecosystem. If a single foundation model can see, hear, speak, and query enterprise databases natively, the market for specialized intermediary models and translation APIs will experience a brutal contraction. Over the next five years, the competitive edge will not belong to the lab with the most impressive video demos, but to the cloud provider that can deliver this multi-sensory intelligence with ironclad SLAs, fail-safes, and predictable economics. The AI race is scaling past raw reasoning - it is now a war of infrastructure orchestration.
Related News

Grok Imagine Odyssey: xAI's Long-Form Video Ambitions
Elon Musk announced Grok Imagine for a full-length, historically accurate Odyssey film. Explore the massive AI infrastructure and temporal consistency challenges this project presents. Learn more.

xAI Grok 4.5 & 4.6: Tavily Integration Cuts Hallucinations
xAI moved Grok web retrieval to Tavily 4 for sharper reasoning and fewer errors. See how this modular approach affects developers, benchmarks, and future model scaling. Learn more.

Kimi K3: Moonshot AI Builds Frontier LLM With Limited Hardware
Moonshot AI's Kimi K3 delivers strong reasoning, coding, and ultra-long context under hardware limits. It gives Chinese enterprises a compliant high-performance option. Explore the analysis.