AI Hallucinations: The Hidden Infrastructure Cost for Enterprises

⚡ Quick Take
Summary
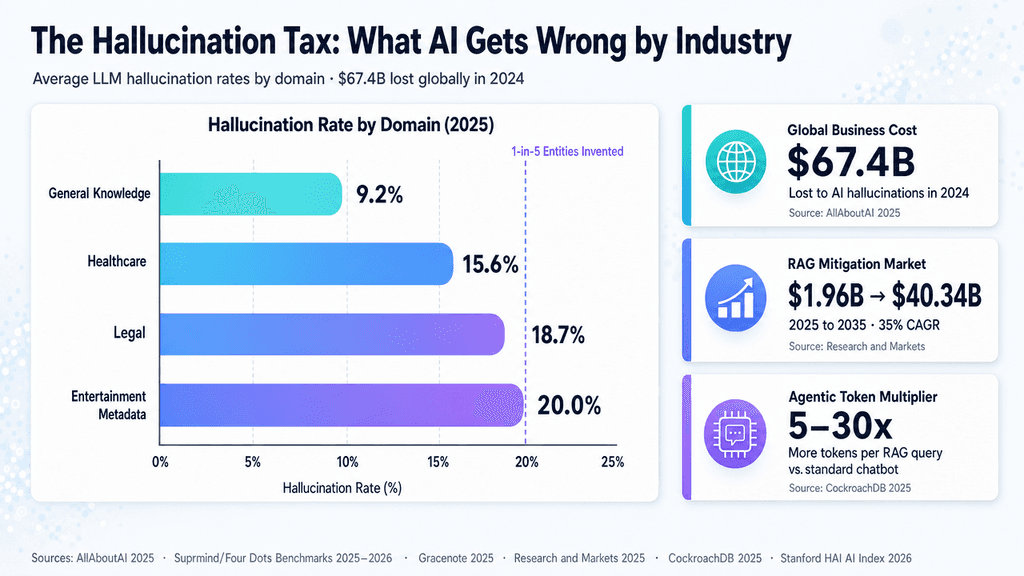
As enterprise AI adoption scales, the narrative around AI hallucinations is shifting from a prompt-engineering quirk to a multi-billion-dollar infrastructure bottleneck. Recent benchmark data shows that base models still hallucinate 1-in-5 industry-specific entities, which has set off a race among cloud and chip providers to build latency-heavy grounding pipelines.
What happened
AI vendors are pointing to the models' core limits. LLMs are prediction engines, not databases, so they produce high rates of confabulation with no grounding in fact. In response, everyone from OpenAI and Anthropic to the big infra players like NVIDIA and Azure has stopped pretending the models can be "fixed" from within. The focus is now on heavier architectural workarounds such as RAG (Retrieval-Augmented Generation), vector databases, and multi-model verification.
Why it matters now
Trust caps how far AI can reach in the market. When domain-specific metadata benchmarks, like Gracenote's entertainment tracking, turn up a 20% failure rate on entity recognition, the cost of any real deployment jumps. Cutting hallucinations means adding extra inference cycles, which multiplies compute use and cloud spend per query.
Who is most affected
Enterprise CTOs and AI infrastructure architects who have to weigh the added latency and cost of secondary "verifier" models and vector search layers against strict corporate SLAs.
The under-reported angle
The true cost of factuality. The industry is still treating hallucination mitigation as a software problem, yet running continuous self-consistency checks, NeMo Guardrails, and RAG pipelines creates a sizable hidden latency tax and effectively doubles inference compute needs.
🧠 Deep Dive
Have you ever watched a fluent answer fall apart the moment someone checks the facts? That gap between smooth output and actual accuracy sits at the heart of the issue. The fundamental nature of Large Language Models—token-by-token statistical prediction—turns hallucination into an architectural feature, not a bug. Even with rapid scaling, base model performance stays tied to the fact that LLMs reward fluency over faithfulness. Earlier coverage framed the problem as something prompt tweaks could solve. Yet the real pressure points are showing up at the infrastructure layer, where the distance between what a model "knows" and what a company can risk is closed only by throwing more compute at it.
Domain-specific datasets make the scale of the issue hard to ignore. A recent Gracenote study found that base models simply invent one in five titles when working with streaming media metadata. In healthcare, finance, or legal settings, a 20% hallucination rate makes autonomous agents impractical. The industry's answer is not to chase a perfectly omniscient model. Instead, work from DeepMind and Anthropic points to multi-agent pipelines that rely on Constitutional AI for self-critique and secondary verifier models whose only role is to cross-check the primary output.
This changes the entire infrastructure stack. To enforce citations and keep outputs grounded, leaders are treating the RAG pipeline as standard practice. Microsoft pushes Azure AI Search hard, while NVIDIA folds NeMo Guardrails into enterprise setups. What few playbooks spell out—yet AI architects keep running into—is the steep cost-latency-quality trade-off. Running a prompt through semantic search, pulling vectorized context, validating the schema, and then firing a secondary factual check means paying for two or three inference cycles on every interaction.
Teams are also moving toward "abstention design." Rather than forcing an answer, they are wiring UI and telemetry to calibrated thresholds. When drops below a TruthfulQA or FactScore benchmark, the system either refuses or routes the query to a human. That turns hallucination from an unpredictable defect into a measurable, risk-managed workflow.
The race to eliminate hallucinations is therefore an infrastructure arms race. The deployments that succeed over the next five years will belong to organizations with the most efficient routing layers—those that can run fast, cheap inference for routine tasks and shift to heavier verification only when the stakes demand it.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Base models are being de-emphasized as standalone products, with attention shifting to APIs that support tool use and verified grounding from the start. |
Infra & Cloud Vendors | High | Hallucination mitigation is driving strong demand for vector databases, external search APIs, and guardrail compute from Azure, AWS, and NVIDIA. |
Enterprise CTOs / Buyers | Significant | ROI models must account for the reality that cutting hallucination rates from 20% to 1% multiplies latency and compute costs. |
Regulators & Policy | Medium-High | Demand is rising for auditable AI practices that map to ISO/IEC 23894, moving factuality from a technical preference to a compliance requirement. |
✍️ About the analysis
This independent, research-based analysis maps the current state of AI factuality controls by synthesizing vendor documentation, recent benchmarking data (including Gracenote tracking and FEVER/FactScore methodologies), and foundational AI research. It is written for AI engineers, data architects, and CTOs who are dealing with the operational realities of enterprise-grade language models.
🔭 i10x Perspective
The hallucination problem shows how intelligence and memory are decoupling in AI systems. The future model is not an isolated brain that holds everything but an agile reasoning engine tied to large, external, and verifiable knowledge sources. For the broader ecosystem—from NVIDIA down to application developers—this means solving hallucinations is not a one-time research win. It is an ongoing economic driver that keeps inference demand running ahead of raw model improvements.
One development worth watching is the rise of "factuality-as-a-service layers, where latency and verification efficiency, not just raw intelligence, will determine who wins in enterprise AI."
Related News

AI Agents Drive Blockchain Micropayments Race
AI agents are evolving into autonomous economic actors, spurring blockchain networks to build instant M2M payment rails. Learn how Solana, Ripple, and Lightning enable sub-cent transactions with strong custody controls. Explore the guide.

Claude 3.5 Sonnet Availability Risks: Geopolitical LLM Impact
Regulatory interventions are reshaping LLM selection for Claude 3.5 Sonnet. Learn why multi-model fallback strategies are now essential for enterprise AI resilience. Explore the guide.

Kimi K2.7-Code: Internal Benchmarks and Transparency Gaps
Moonshot AI launched Kimi K2.7-Code with a 21.8% internal improvement claim, but lacks comparisons on public benchmarks. Explore the implications for enterprise coding AI adoption.