Kimi K2.7-Code: Internal Benchmarks and Transparency Gaps

⚡ Quick Take
Moonshot AI has officially rolled out Kimi K2.7-Code. claiming a 21.8% performance jump over its predecessor. But as the enterprise AI ecosystem rapidly pivots toward repository-scale reasoning and multi-file refactoring, leaning on proprietary internal benchmarks over public stress-tests leaves the market searching for real-world validation.
Summary:
Moonshot AI has introduced Kimi K2.7-Code, presenting it as a major evolutionary step in its coding-specific model lineage. Driven by a data-point-led marketing approach, the release heavily points to internal testing on Kimi Code Bench V2 to demonstrate superiority over the K2.6 build, though it notably omits comparisons to global open-source and proprietary heavyweights.
What happened:
The Chinese AI startup launched its newest code-generation model, focusing almost entirely on a 21.8% accuracy and completion improvement relative to its last generation. The announcement, echoed by early tech aggregators, aims to cement Kimi’s viability as a dedicated programming assistant without disclosing the underlying datasets or context length parameters that define the upgrade.
Why it matters now:
Have you ever watched a new model land with fanfare only to realize the numbers live in a vacuum? Coding models are the current ultimate proxy for reasoning capabilities in LLMs. The transition from merely generating a Python script to actively participating in complex software development lifecycles requires high pass@k rates, low inference latency, and RAG-for-code integrated tooling. K2.7-Code’s release highlights how regional AI vendors are aggressively segmenting models to capture developer ecosystems, racing against dominant platforms.
Who is most affected:
Engineering leaders evaluating cost-effective LLM backends for internal tooling, AI developers building coding agents, and direct competitors in the specialized code-llm space (such as DeepSeek, Alibaba, Anthropic, and OpenAI).
The under-reported angle:
Everyone is reporting the 21.8% internal benchmark bump, but no one is asking the hard evaluation questions. Without transparent head-to-head comparisons against SWE-bench or HumanEval+, or details on repository-level code synthesis within Kimi’s famously massive context windows, this is a black-box model asking for blind enterprise trust.
🧠 Deep Dive
Moonshot AI’s release of Kimi K2.7-Code arrives at a critical inflection point in the AI development timeline. As the mainstream tech press dutifully parrots the PR-friendly "21.8% improvement" metric mapped against "Kimi Code Bench V2," the broader AI infrastructure community is recognizing a growing pain point: the divergence between marketing benchmarks and real-world developer friction. Grading your own homework in 2024–2025 is no longer sufficient when enterprise CTOs are demanding transparent ROI and granular failure mode analysis before deploying models to production codebases.
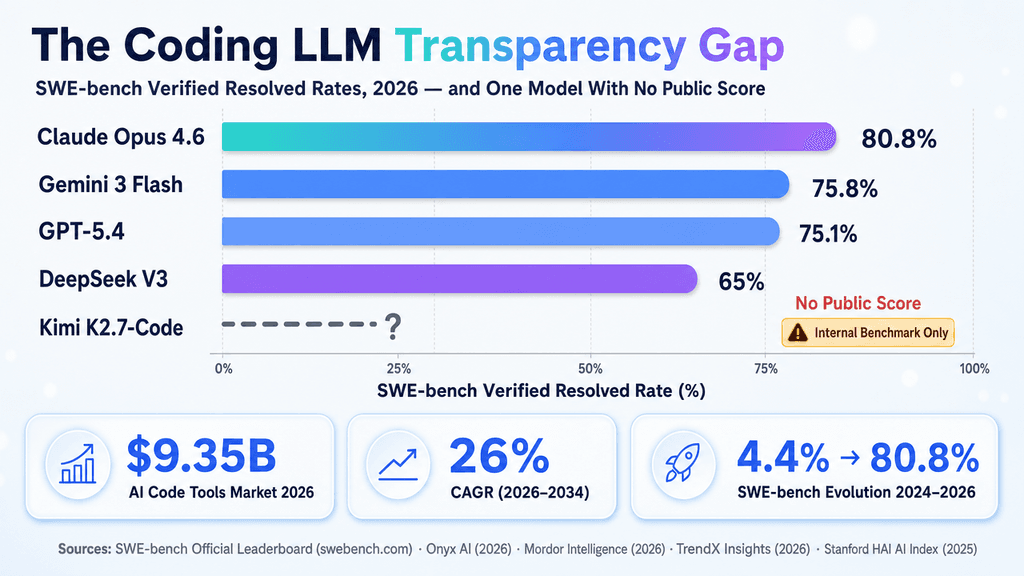
To understand K2.7-Code’s true impact, we have to look at what is absent from the current discourse. The industry standard has shifted toward independent validation suites like MBPP+, SWE-bench, and AtCoder-style logic testing. By anchoring its narrative solely to K2.6, Moonshot bypasses direct confrontation with highly optimized market leaders like Claude 3.5 Sonnet, GPT-4o, and the open-weights disruptor DeepSeek-Coder. For an engineering leader deciding whether to upgrade or migrate, a lack of pass@1 metrics, API latency transparency, and context-window capabilities makes the model difficult to deploy natively.
That said, Kimi’s historical DNA offers a compelling, overlooked angle: long-context reasoning. Moonshot pioneered the ultra-long context window (pushing into millions of tokens) early in the AI race. If K2.7-Code effectively leverages this capability for RAG-for-code applications and repository-level code synthesis, it fundamentally alters the physics of how a developer interacts with it. Instead of merely writing a unit test, an AI agent armed with this architecture could theoretically hold an entire legacy Java or C++ codebase in memory, tracking static analysis and semantic logic loops in a single inference call.
From what I've seen with similar long-context releases, the stakes for this kind of infrastructure stretch far beyond basic SaaS tooling. Implementing AI that alters code involves serious IP, copyright, and security considerations—areas entirely glossed over by early coverage. Without documentation on deduplication from training data, CWE-aware security filters, or specific IP protections, enterprise adoption will stall at the prototype phase. Code generation is essentially translating human intent into actionable computing; models that fail to safeguard this process are liabilities, no matter how quickly they write a boilerplate class.
Ultimately, the competitive distance between K2.7-Code and its peers will be measured not in PR cycles, but in the trenches of developer hubs. Reproducibility assets—like seeds, system prompts, evaluation scripts, and multi-language API quickstarts—are the modern currency of model adoption. As AI models continue to hyper-specialize, Moonshot’s technical rollout will need to mature rapidly, moving past insular benchmarks to prove its mettle in the brutal, edge-case-heavy reality of commercial software engineering.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Competitors | Medium | Incremental pressure on regional rivals (e.g., DeepSeek, Qwen) to maintain their edge in open benchmarks and developer SDKs. |
Engineering Teams & CTOs | High | Potential access to a powerful new specialized engine, but hampered by a lack of transparent migration guides, API pricing, and rigorous public baselines. |
AI Infrastructure Providers | Medium | Specialized coding models require different inference optimization (low latency, high single-stream throughput). Demands cloud alignment. |
Security & Compliance | Significant | Use of opaque coding models raises questions about code provenance, security vulnerabilities (SAST friction), and IP copyright safety. |
✍️ About the analysis
This independent, research-based analysis distills the media and technical landscape surrounding Moonshot AI's latest model drop, moving beyond surface-level PR. It is designed for CTOs, engineering managers, and ML practitioners who require clear signal regarding benchmark rigor, competitive model tracking, and the evolving dynamics of AI-assisted software engineering.
🔭 i10x Perspective
The release of Kimi K2.7-Code highlights a deepening fault line in the AI trajectory: the tension between proprietary corporate metrics and the open-source demand for verifiable reasoning baselines. As coding becomes the fundamental testbed for AGI—requiring rigorous logic, tool use, and multi-step execution—the tolerance for black-box benchmark claims is rapidly expiring. For the next 5 years, the victors won’t simply be the labs that build the heaviest parameter models; they will be the ones that deliver frictionless, secure, and verifiably integrated intelligence right to the edge of the developer's IDE. Open evaluation isn't just a research nicety-it is the new enterprise go-to-market mandate.
Related News

AI Hallucinations: The Hidden Infrastructure Cost for Enterprises
Base models hallucinate 1 in 5 domain entities. Learn how RAG, verifier models, and factuality layers are driving AI infrastructure changes and raising compute costs. Explore the guide.

AI Agents Drive Blockchain Micropayments Race
AI agents are evolving into autonomous economic actors, spurring blockchain networks to build instant M2M payment rails. Learn how Solana, Ripple, and Lightning enable sub-cent transactions with strong custody controls. Explore the guide.

Claude 3.5 Sonnet Availability Risks: Geopolitical LLM Impact
Regulatory interventions are reshaping LLM selection for Claude 3.5 Sonnet. Learn why multi-model fallback strategies are now essential for enterprise AI resilience. Explore the guide.