AI Rationing: GPU Bottlenecks Force Shift to SLMs

⚡ Quick Take
As Silicon Valley pours unprecedented billions into its infrastructure, the race for artificial intelligence has collided with physical and economic brick walls, triggering widespread "AI rationing" across the tech ecosystem.
Summary: Facing structural GPU bottlenecks and maxed-out power grids, hyperscalers are actively rationing compute access, forcing Wall Street and tech leaders to question whether the current AI massive capital expenditure (capex) surge is a sustainable buildout or a speculative bubble.
What happened: Major cloud providers have quietly instituted strict GPU allocation policies, prioritizing enterprise heavyweights while throttling compute availability for smaller pilots, effectively gatekeeping who can train and run large language models (LLMs) at scale.
Why it matters now: The narrative is shifting from unconstrained scaling to harsh unit economics; as the cost to serve AI queries remains high, the pace of AI diffusion is being throttled not by lack of capital, but by lack of accessible, affordable compute and energy.
Who is most affected: CTOs, AI developers, and SMEs attempting to deploy complex inference workloads, alongside utility providers who are scrambling to manage multi-year grid interconnect queues for new gigawatt-scale data centers.
The under-reported angle: While mainstream coverage focuses on big tech stock valuations and semiconductor supply chains, the actual forcing function of AI rationing is driving a massive, silent enterprise shift toward open-source Small Language Models (SLMs) and quantization techniques to bypass the hyperscaler GPU bottleneck entirely.
🧠 Deep Dive
Have you ever stared at a deployment timeline that suddenly stretched from months to years? To understand the current state of the AI ecosystem, look past the staggering $100B+ capex guidance from hyperscalers and look at the waiting lists. "AI rationing" has become the defining operational reality of 2024. Cloud vendors are actively triaging access to premium NVIDIA silicon, forcing enterprises to negotiate reserved compute pools or share capacity.
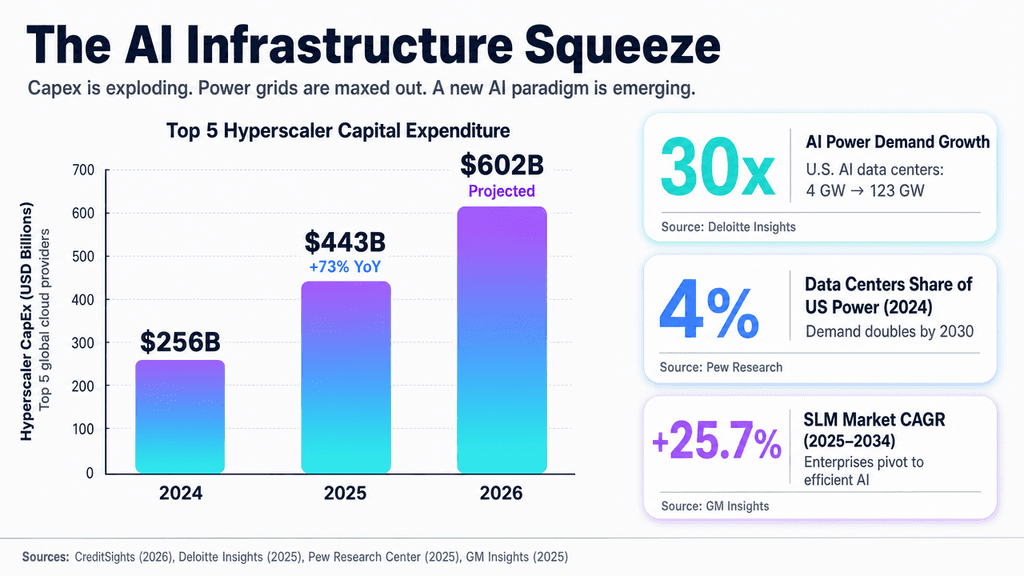
Mainstream financial media keeps debating whether this echoes the dot-com bubble or the railway mania. But the real crisis stems from a collision between exponential software ambitions and linear physical infrastructure.
The most impenetrable bottleneck isn't capital—it's physics. The energy required to sustain gigawatt-scale AI campuses is hitting hard limits. Regional permitting realities, power purchase agreements (PPAs), and grid interconnect queues now dictate where intelligence can expand. You cannot deploy tens of thousands of GPUs if the local utility requires five years to upgrade transmission lines. This energy crunch directly creates compute scarcity, acting as an artificial ceiling on next-generation frontier models. From what I've seen, this constraint hits smaller teams hardest.
This physical scarcity is violently reshaping the unit economics of AI. We are exiting the era of "train everything" and entering the era of inference optimization. Hyperscalers face immense investor pressure to prove massive capex investments translate into real revenue and ARPU uplift. As a result, the cost-per-query for running massive LLMs sits under a microscope. If an AI feature costs more in compute than users will pay, progress stalls.
That said, constraints breed innovation. The rationing of compute is inadvertently accelerating a parallel AI ecosystem. Enterprises tired of waiting for GPU priority are shrinking dependence on monolithic models. Rapid adoption of Small Language Models (SLMs) and efficient open-source architectures is underway—models that run on consumer-grade hardware or CPUs. Techniques like distillation and quantization have shifted from academic exercises to survival tools for SMEs integrating AI without hyperscaler gatekeeping.
Ultimately, the rationing phenomenon pushes a healthy maturation. It moves the burden from management hype to verifiable metrics like attach rates, capex efficiency, and time-to-payback. The AI revolution isn't a bubble about to pop. It is a platform transition bottlenecking at the infrastructure layer, and that changes how intelligence gets priced and packaged over the next decade.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Forced to optimize model architectures aggressively; prioritizing API stability for enterprise clients over experimental features. |
Data Centers & Utilities | Highest | Grid power availability is now the top leading indicator for AI capacity. Real estate is secondary to megawatt access. |
SMEs & Developers | High | Locked out of high-end compute, accelerating the pivot to open-source SLMs and localized inference hardware. |
Investors & Markets | Medium | Shifting focus from raw capex numbers to margin impacts, revenue-per-query, and true AI monetization KPIs. |
✍️ About the analysis
This independent analysis is synthesized from real-time search intent data, cross-market financial reporting, and infrastructure supply-chain metrics. It is designed for CTOs, AI ecosystem builders, and infrastructure strategists navigating the transition from the theoretical AI hype cycle into the hard realities of deployment economics.
🔭 i10x Perspective
AI rationing isn't a temporary glitch; it is a structural forcing function that will permanently bifurcate the AI market. On one end, a small oligopoly of well-capitalized players will keep building massive AGI-oriented clusters, heavily constrained by nuclear energy timelines and sovereign grid policies. On the other, the compute drought is birthing a resilient, hyper-efficient shadow ecosystem of commoditized edge models. Over the next five years, the most valuable AI companies won't necessarily be those with the largest GPU clusters, but the ones generating the highest intelligence-per-watt without relying on centralized gatekeepers.
Related News

Agentic Zero Trust: Securing Autonomous AI Agents
Explore why Agentic Zero Trust is essential for AI agents executing real tasks. Learn about biometric security, human oversight, and enterprise controls to mitigate risks. Discover how to implement it effectively.

G7 Summit: Frontier AI Labs and Compute Governance
Explore how the G7 Summit is shaping frontier AI through compute governance, bringing labs and states together on safety and policy. Learn more about the implications for AI regulation.

GLM-5.2: Optimized for Long-Horizon Multi-Step AI Tasks
GLM-5.2 tackles compounding errors in extended AI workflows with built-in hierarchical reasoning. Discover its impact on autonomous agents and infrastructure needs. Explore the guide.