AI Inference Hardware Shift: Custom Chips vs NVIDIA

Quick Take: The AI Inference Hardware Shift
⚡ Quick Take
Summary: The AI hardware race is aggressively shifting from highly centralized model training to the fragmented, margin-critical battlefield of inference compute.
What happened: Top-tier players like OpenAI are now partnering with Broadcom to build custom AI inference chips, accelerating a broader market divergence where dedicated silicon—ranging from AWS Inferentia to Groq’s LPUs and Google’s TPUs—is rising to challenge NVIDIA’s dominance.
Why it matters now: While enterprise AI adoption scales, the "invisible tax" on intelligence—latency and cost-per-token—threatens profitability. From what I've seen, optimizing the inference layer through specialized hardware and software (like TensorRT-LLM and vLLM) is the only way to make generative AI economically viable at scale.
Who is most affected: Cloud architects, ML infrastructure engineers, and enterprise CTOs who must now navigate a complex matrix of chip choices, compiler compatibility, and hardware lock-in to avoid burning through budgets.
The under-reported angle: The true bottleneck is no longer just silicon speed, but software interoperability. The war will be won by whichever ecosystem simplifies the messy reality of compiling, quantizing, and running models across diverse hardware without sacrificing accuracy.
🧠 Deep Dive
Have you noticed how the conversation around AI shifted once models moved out of the lab? Training a monolithic LLM is a brutal feat of raw compute, traditionally demanding massive clusters of NVIDIA GPUs. But deploying that model into production—inference—is where the real economic gravity of AI lies. As foundational models become table stakes, the generative AI market is realizing that running these models on general-purpose GPUs is akin to using a sledgehammer for a scalpel's job. This realization has triggered an explosion of specialized AI inference chips designed to slash the cost per token and hit rigid p95 latency Service Level Agreements (SLAs).
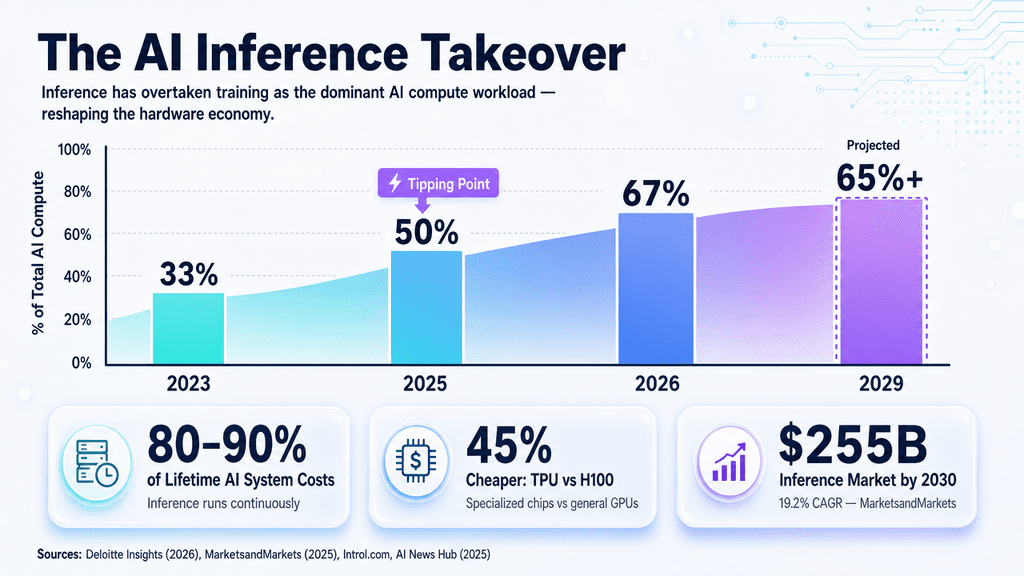
The competitive landscape is splintering rapidly into distinct philosophies. NVIDIA is defending its throne through ecosystem lock-in, pairing raw GPU power with its proprietary TensorRT-LLM and Triton Inference Server to promise maximum performance and deploy-anywhere flexibility. Cloud hyperscalers are weaponizing their infrastructure in parallel. AWS pitches its custom Inferentia silicon as a pure Total Cost of Ownership (TCO) play, offering deep discounts to pull workloads away from GPUs. Google leverages its TPUs and XLA compiler to natively string together massive global networks. Meanwhile, insurgents like Groq are attacking latency head-on, deploying LPUs (Language Processing Units) that boast deterministic, ultra-low latency for user-facing applications where a few extra milliseconds can kill a product experience.
Yet, as builders hunt for alternatives, the underlying tension moves from the hardware layer to the supply chain and software stack. OpenAI's recent partnership with Broadcom to co-design custom inference silicon highlights a stark reality: even the primary architects of the AI boom are desperate to diversify away from NVIDIA's supply constraints and premium pricing. For the enterprise, the build-vs-buy calculation is shifting. Buying into AMD’s MI300 or Intel’s Gaudi2 opens up an open-source (ROCm) and cost-optimized ecosystem, but it introduces the friction of migrating models optimized for CUDA.
What single-vendor marketing materials obscure is that reducing inference spend by 30% to 70% is rarely just a hardware swap. True optimization happens at the intersection of chip architecture and aggressive software engineering. Techniques like multi-precision quantization (shrinking models to FP8 or INT8), paged attention for KV cache management, and dynamic batching via open runtimes like vLLM are acting as the great equalizers across hardware platforms.
Ultimately, the geographic and environmental footprints of these inference fleets will force a reckoning. As millions of daily API calls strain power grids, the metric of "watts per token" is transitioning from a niche engineering concern to a core boardroom pillar. Moving inference from hyperscale data centers closer to the edge—powered by efficient accelerators like Qualcomm's Cloud AI 100—will be the next frontier for latency-sensitive, privacy-constrained deployments.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
AI / LLM Providers | High | Profitability hinges entirely on minimizing inference costs. Shift toward proprietary ASICs (OpenAI + Broadcom) reshapes vendor dependency. |
Cloud & Infra Architects | High | Tasked with complex bin-packing, managing utilization, and matching specific instances (GPUs vs TPUs vs LPUs) to RAG, batch, or real-time pipelines. |
Chip Vendors (NVIDIA, AMD, Groq) | High | NVIDIA pushes software moats (CUDA/Triton); challengers must prove standard open-source runtimes (ONNX/vLLM) can deliver seamless portability and superior ROIs. |
Grid Operators & Sustainability | Medium–High | The explosion of inference compute shifts data center demand patterns; "watts per token" and localized grid stress become core regulatory issues. |
✍️ About the analysis
This analysis synthesizes independent intelligence, derived from direct competitive positioning, cross-vendor benchmark claims, and technical search intent data. It is constructed for CTOs, ML infrastructure leads, and AI strategists navigating the fragmented compute market aiming to design cost-effective, high-throughput AI deployment architectures.
🔭 i10x Perspective
The commoditization of AI inference hardware is inevitable, but it won't be a peaceful transition. Over the next five years, the narrative will shift from "who possesses the fastest silicon" to "who owns the most frictionless, cross-platform inference compiler."
While NVIDIA dominates the training era, the deployment era will likely belong to open runtimes that abstract away the underlying hardware—turning inference compute into a utility as liquid and tradable as bandwidth. Watch for intense M&A activity as cloud giants and foundational model builders acquire custom silicon design teams to vertically integrate intelligence from the power plug all the way to the prompt layer.
The single most important battleground will be the ecosystem that reduces developer friction and operational complexity—who owns the most frictionless, cross-platform inference compiler.
Related News

Mistral OCR 4: Self-Hosted OCR Engine for Private Enterprise AI
Mistral OCR 4 delivers a self-hosted Document AI engine supporting 170 languages. Run accurate extraction on-premises to cut TCO, meet GDPR and HIPAA requirements, and power private RAG pipelines.

Gemini 3.5 Flash Computer Use: Enterprise AI Automation
Google's Gemini 3.5 Flash now offers native computer use for autonomous desktop and UI automation. Learn how it challenges RPA with built-in safety and compliance features for enterprises.

Meta's Reverse Acqui-Hire of Kunal Shah: New Talent Playbook
Meta is reportedly using a reverse acqui-hire to bring Cred founder Kunal Shah into its ecosystem. Explore how this bypasses traditional M&A and antitrust scrutiny in the AI talent wars. Learn more.