Enterprise AI FinOps: Controlling LLM Inference Costs

⚡ Quick Take
Enterprise AI is transitioning from an era of unchecked experimentation into a brutal phase of unit economics, where unpredictable inference costs are colliding with tight corporate budgets.
Summary: Rising compute and licensing fees are forcing enterprises to actively curb AI usage, shifting the market’s focus from sheer frontier model capabilities to ruthless cost optimization, ML caching, and AI FinOps.
What happened: Across the ecosystem, companies are imposing token quotas, truncating model context windows, and diversifying away from single-vendor API reliance, while cloud providers roll out platform-specific cost guardrails to avoid mid-cycle budget blowouts.
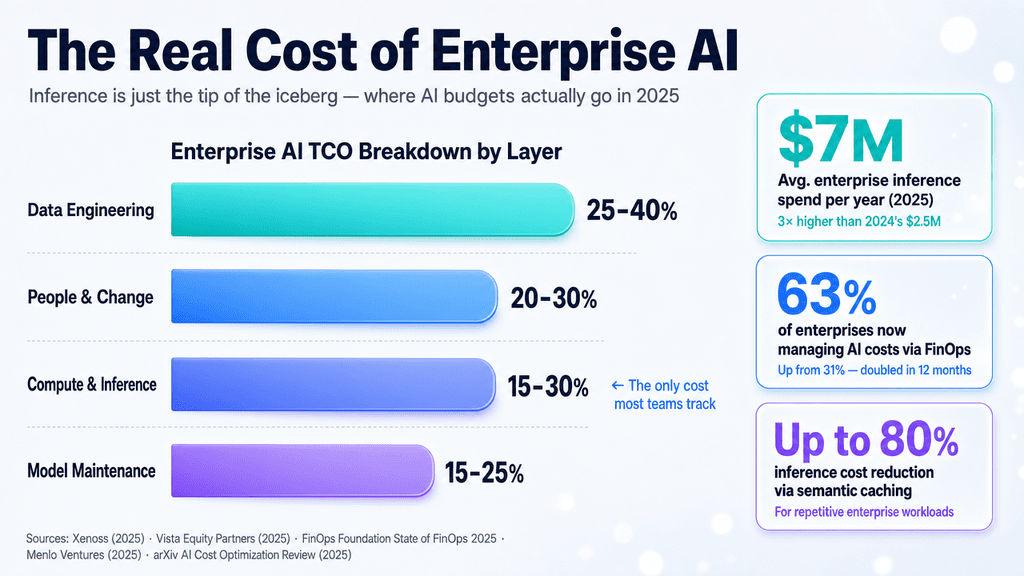
Why it matters now: Inference is rapidly becoming the dominant wedge of AI TCO (Total Cost of Ownership). If developers and CTOs cannot prove that the reasoning-per-dollar ratio of a generative AI deployment works at scale, enterprise LLM adoption will stall in the pilot phase.
Who is most affected: C-suite executives (CFOs, CIOs) trying to rein in shadow AI spend, ML Ops engineers tasked with implementing latency-versus-cost trade-offs, and cloud/model vendors facing heightened pressure from model-routing and multi-vendor diversification.
The under-reported angle: Most TCO narratives focus purely on model per-token pricing, completely ignoring the massive hidden costs of generative AI: RAG architectures' vector database egress fees, continuous evaluation workflows, system guardrails, and the steep premium paid for provisioned concurrency to meet latency SLAs.
🧠 Deep Dive
The generative AI honeymoon is officially over. Driven by an initial mandate to innovate at all costs, enterprises are now staring down massive, unpredictable monthly cloud bills. Recent financial reporting on enterprise budget pressures shows how unrestrained LLM API usage has triggered a market correction. From what I've seen, we're witnessing a hard pivot from "what can this model do?" to "what does it cost to generate this outcome?" As a result, C-suites are mandating strict AI FinOps - instituting token chargebacks mapped directly to business unit ROI.
The underlying tension lies in the architecture of intelligence infrastructure. While training frontier models requires monumental CapEx investments (the $1B+ clusters), inference at scale acts as a relentless OpEx drain. Major players like NVIDIA and hyperscalers (AWS, GCP, Databricks) keep pushing hardware-software co-optimization to drive down cost-per-request. Yet developers often deploy brute-force, sprawling monolithic models for trivial tasks anyway. Low GPU utilization, memory-heavy KV caches, and bloated contextual prompts in RAG setups keep inflating costs.
To bridge this gap, ML engineering teams are digging into the infrastructure weeds. There is a rapid shift toward techniques like INT8/INT4 quantization, sparsity, and speculative decoding to squeeze more throughput out of existing GPU clusters. At the same time, software-layer optimizations - particularly semantic caching, where similar queries route to a cached response instead of a fresh generation - are becoming mandatory. The cloud platforms are responding with their own fixes: Vertex AI and AWS Bedrock now push autoscaling policies, latency tiering, and prompt summarization guardrails to stop the bleeding.
That said, the real enterprise solution is shifting toward provider-agnostic agility. Vendor lock-in is increasingly viewed as a critical TCO risk. Relying entirely on a single API endpoint exposes companies to sudden price hikes and limits their ability to route simple tasks to cheaper models. The industry is quietly adopting dynamic model routers and Mixture-of-Experts principles at the deployment level. An advanced enterprise pipeline today might route complex logic to GPT-4 or Claude 3.5 Sonnet, while offloading routine text summarization to a highly compressed, fine-tuned Llama 3 or Mistral on serverless infrastructure.
Ultimately, this cost squeeze is reshaping the AI software supply chain. The hidden costs - guardrail latencies, specialized data prep, and high egress fees from vector databases - are proving just as expensive as the compute itself. Until the market establishes standardized, provider-agnostic per-token pricing benchmarks tied to objective quality metrics, enterprise deployment will remain a high-stakes balancing act.
📊 Stakeholders & Impact
Stakeholder / Aspect | Impact | Insight |
|---|---|---|
Enterprise C-Suite (CFO/CIO) | High | Forcing the adoption of "AI FinOps," deploying showback/chargeback models to tie token consumption directly to business ROI. |
ML/Platform Engineers | High | Shifting priorities from feature creation to infrastructure optimization (quantization, semantic caching, vector DB egress management). |
Cloud Providers & LLM Vendors | Medium–High | Forced to offer more granular cost controls, serverless tiers, and smaller models to prevent customer churn. |
AI Infrastructure (NVIDIA) | Significant | Accelerating demand for inference-optimized software layers (like TensorRT-LLM) to maximize hardware utilization and efficiency. |
✍️ About the analysis
This independent, research-based analysis tracks the TCO dynamics and architectural shifts in the enterprise generative AI market. Drawing from major cloud platform cost-control playbooks, hardware utilization benchmarks, and C-suite deployment reports, it aims to help CTOs, ML engineering leaders, and FinOps practitioners navigate the economics of scaling LLMs.
🔭 i10x Perspective
The current panic over AI costs is merely the growing pain of an industry moving from brute-force scale to precision engineering. Over the next five years, intelligence will be metered and optimized just like cloud compute or electricity. This pressure is already accelerating autonomous model routing - where hyper-specialized SLMs (small local models) handle 80% of enterprise workloads, reserving expensive frontier LLMs strictly for complex reasoning. For AI providers, the ultimate moat won't just be having the most capable model, but delivering the most efficient unit-cost of intelligence.
Related News

Localized LLMs in Restaurants: Adoption Benefits & Risks
Restaurants adopt localized LLMs to cut admin time and manage operations amid labor shortages. Learn the benefits, integrations, and critical compliance risks around allergen safety. Explore the guide.

Google AI Overviews: Why Enterprises Bypass Gemini Integration
Google’s Gemini AI Overviews now dominate search results, pushing down traditional links. Learn why publishers and IT teams rely on udm=14 workarounds and what this means for traffic, compliance, and compute costs. Explore the analysis.

Agentic Zero Trust: Securing Autonomous AI Agents
Explore why Agentic Zero Trust is essential for AI agents executing real tasks. Learn about biometric security, human oversight, and enterprise controls to mitigate risks. Discover how to implement it effectively.