Gemini 1.5 Edges Out Copilot in AI-First Search

Summary
Google's Gemini appears to be pulling ahead of Microsoft Copilot when it comes to AI-first search, and that shift feels like more than just another round of model hype. It points to a real change in how these systems handle speed and context at scale.
What happened: Recent market looks suggest the Gemini 1.5 Pro and Flash family has been woven deeper into Google's search stack, giving it an edge over Copilot's GPT-4o setup on tougher, multi-step questions where accuracy and context matter most.
Why it matters now: Search serves as the toughest proving ground for AI systems. Success here hinges on delivering near-instant answers, running clean RAG pipelines, and keeping compute costs in check.
Who is most affected: Developers shaping enterprise search tools, CTOs weighing which models to run in production, the infrastructure teams handling inference loads, and publishers watching their traffic patterns change.
The under-reported angle: Most coverage frames this as a simple head-to-head between products, yet it glosses over the missing piece: reliable, open benchmark numbers. The real contest sits in p50 and p95 latency figures, how faithfully sources get cited, and the ongoing trade-off between fewer hallucinations and cost per query.
🧠 Deep Dive
Have you ever wondered why some AI answers feel crisp while others stumble on the same topic? The idea that Gemini is overtaking Copilot in search goes beyond product bragging. It shows how Google's infrastructure choices are settling into place. Its early generative efforts felt sluggish by comparison. Now the focused use of Gemini 1.5 Flash for fast, cheaper inference reveals a clearer plan—one that Copilot is still working to match on complex queries.
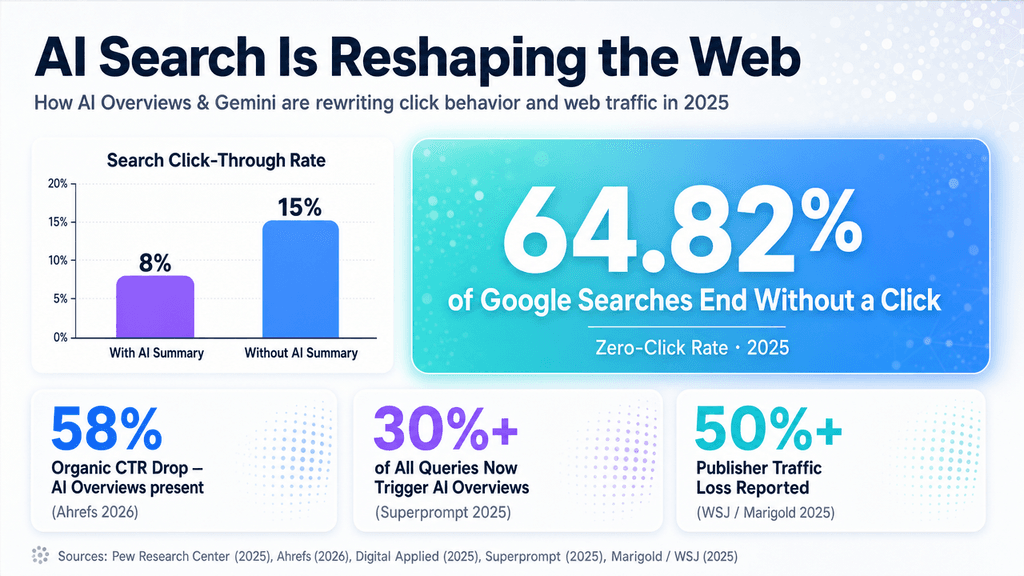
Standard reports often lean on vague claims of “smarter” results without showing the numbers that would back them up. Developers and teams evaluating these tools really need clear data on citation quality, how often links appear, and when models simply refuse to answer. The difference between an okay response and a dependable one usually comes down to keeping p95 latency low even as context windows grow, all while avoiding stray fabrications.
This change also ripples through how content gets found and credited online. With AI Overviews taking up more space on results pages, questions around where the information comes from grow louder. Google continues testing ways to credit publishers while still offering summarized answers, including signals like SynthID to mark generated text.
Microsoft faces its own constraints. Copilot's dependence on GPT-4o pushes constant compromises around speed, local grounding, and privacy settings. Watching this matchup gives enterprise buyers and builders a practical sense of what works for secure, fast retrieval at scale. The systems that combine strong privacy controls with quick, well-sourced answers will shape what gets built next.
In the end, the current Gemini push signals a move away from simply making bigger models and toward squeezing more performance out of inference itself. As both companies refine how search blends with generative replies on phones and desktops, the data centers behind them face tighter demands on routing and token delivery.
📊 Stakeholders & Impact
- AI / LLM Providers
Impact: High
Insight: Escalates the need for highly optimized, low-latency models (like Gemini Flash) over massive, slower models in consumer routing layers. - Infrastructure & Cloud
Impact: High
Insight: AI-first search drives a permanent spike in ongoing inference compute requirements, stressing data center power and GPU allocation. - Digital Publishers / SEO
Impact: High
Insight: Generative search alters traditional click-through traffic, forcing publishers to adapt to AI citation behaviors and semantic retrieval priorities. - Web Developers & Enterprise
Impact: Medium–High
Insight: Sets the gold standard for how RAG architectures must perform regarding speed, factual accuracy, and data privacy in commercial applications.
✍️ About the analysis
This independent review pulls together current search patterns, gaps in public benchmarks, and what developers are actually dealing with. It is written for CTOs, product leads, and engineers who track how these models get deployed in real retrieval systems.
🔭 i10x Perspective
From what I've seen, the winner in this Gemini vs. Copilot contest will not be settled by nicer interfaces. It will come down to who manages the basic cost of running inference at global scale. As these models turn into the main layer for finding information, traffic flows and compute priorities are being rearranged. Over the next several years, the push-and-pull between instant AI summaries and the need for original sources to stay viable will likely trigger both technical and regulatory adjustments across the field.
Related News

Meta's Reverse Acqui-Hire of Kunal Shah: New Talent Playbook
Meta is reportedly using a reverse acqui-hire to bring Cred founder Kunal Shah into its ecosystem. Explore how this bypasses traditional M&A and antitrust scrutiny in the AI talent wars. Learn more.

LinkedIn GEO: Shaping AI Citations in ChatGPT & Perplexity
Learn how LinkedIn activity drives Generative Engine Optimization, feeding verified signals into AI search like Perplexity and ChatGPT. Master Entity SEO tactics now. Explore the guide.

US Restricts Anthropic AI Model Over National Security Risks
The U.S. government intervenes on Anthropic’s latest model citing security concerns. Explore impacts on enterprises, infra providers, and strategies for multi-model resilience.